缓存预热+缓存雪崩+缓存击穿+缓存穿透
缓存预热

使用@PostConstruct初始化白名单数据
缓存雪崩
发生
- redis主机挂了,redis 全盘崩溃,偏硬件运维
- redis中有大量key同时过期大面积失效,偏软件开发
预防+解决
- redis中key设置为永不过期或过期时间错开
- redis缓存集群实现高可用
- 主从节点
- Redis Cluster(redis集群)
- 开启redis持久化机制aof/rdb,尽快恢复缓存集群
- 多缓存结合预防雪崩
- ehcache本地缓存+redis缓存
- 服务降级
- Hystrix或者阿里Sentinel限流&降级
- 人民币玩家
- 阿里云数据库Redis版
- 数据库上云优选_数据库产品低至3折起-阿里云权益中心
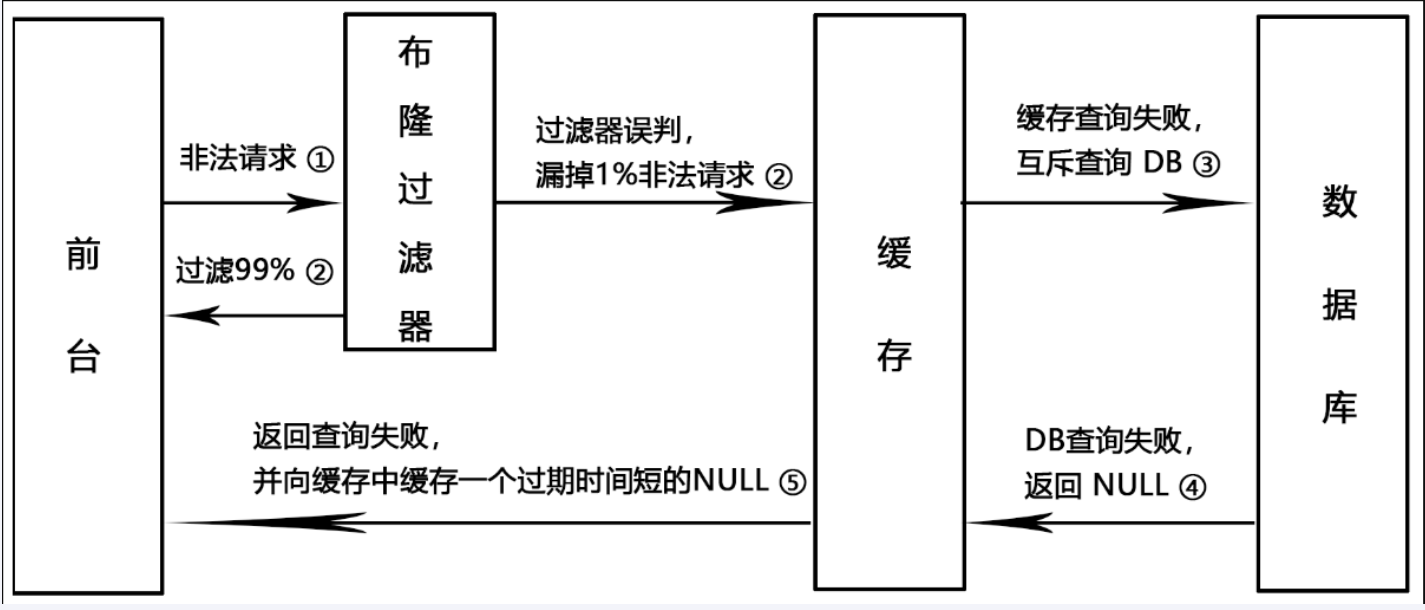
缓存穿透
请求去查询一条记录,先查redis(无),后查mysql(无),都查不到该条记录,但是请求每次都会打到数据库上面去,导致后台数据库暴增,这种现象称为缓存穿透。
解决

空对象缓存或者缺省值(只能解决暂时)
一般ok
- 第一种解决方案,回写增强
如果发生了缓存穿透,我们可以针对要查询的数据,在Redis里存一个和业务部门商量后确定的缺省值(比如,零、负数、defaultNull等)。
比如,键uid:abcdxxx,值defaultNull作为案例的key和value
先去redis查键uid:abcdxxx没有,再去mysql查没有获得 ,这就发生了一次穿透现象。
but,可以增强回写机制
mysql也查不到的话也让redis存入刚刚查不到的key并保护mysql。
第一次来查询uid:abcdxxx,redis和mysql都没有,返回null给调用者,但是增强回写后第二次来查uid:abcdxxx,此时redis就有值了。
可以直接从Redis中读取default缺省值返回给业务应用程序,避免了把大量请求发送给mysql处理,打爆mysql。
但是,此方法架不住黑客的恶意攻击,有缺陷……,只能解决key相同的情况
但是黑客或者恶意攻击
- 黑客会对你的系统进行攻击,拿一个不存在的id去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉。
- key相同打你系统
- 第一次打到mysql,空对象缓存后第二次defaultNull缺省值,避免mysql被攻击,不用再到数据库中去走一圈了
- key不同打你系统
- 由于存在空对象缓存和缓存会写(看自己业务不限死),redis中的无关紧要的key也会越写越多(记得设置redis过期时间)
Google布隆过滤器Guava解决缓存穿透
Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们可以直接使用Guava布隆过滤器
案例
架构说明
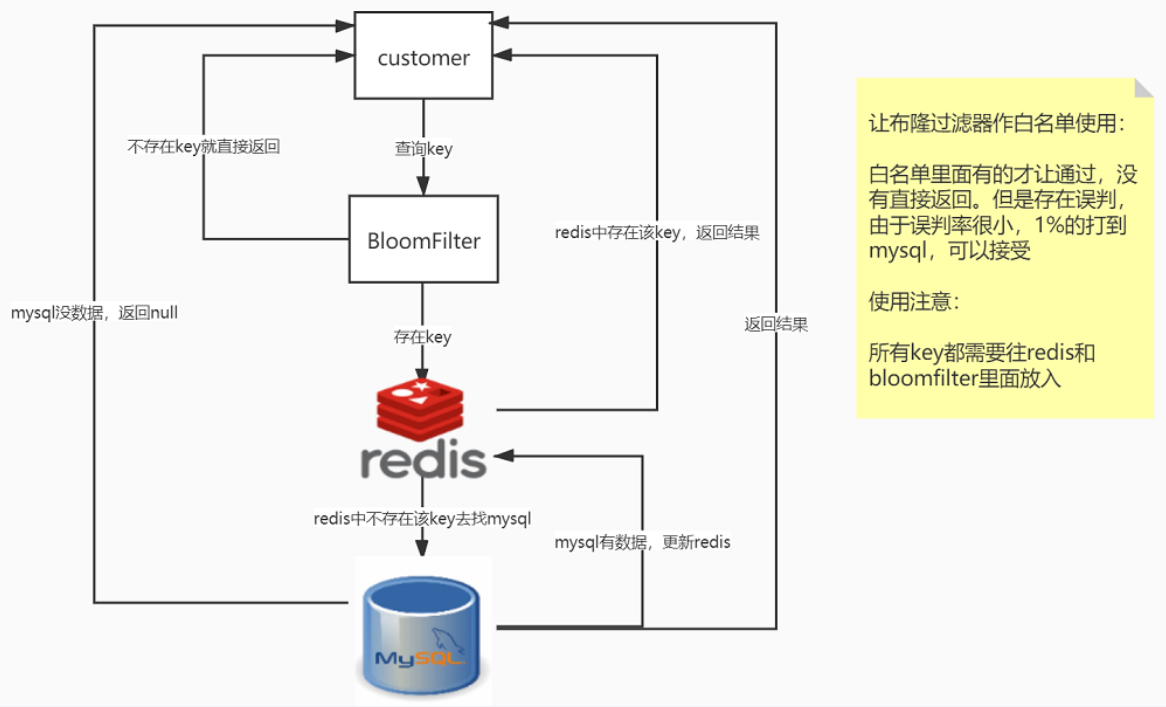
误判问题,但是概率小可以接受,不能从布隆过滤器删除
全部合法的key都需要放入Guava版本布隆过滤器+redis里面,不然数据就是返回null
pom<!--guava Google 开源的 Guava 中自带的布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>yamlserver:
port: 8080
spring:
application:
name: Redis7_study
data:
redis:
host: 192.168.0.133 # redis IP 地址
database: 0 # redis 0号数据库
port: 6379 # redis 端口
password: redis # redis 密码
lettuce:
pool: # lettuce 连接池
max-active: 8 # 连接池最大连接数
max-wait: -1ms # 连接池最大阻塞等待
max-idle: 8 # 连接池最大空闲连接
min-idle: 0 # 连接池最小空闲连接小demo
package com.lazy;
import com.alibaba.google.common.hash.BloomFilter;
import com.alibaba.google.common.hash.Funnels;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
class Redis7StudyApplicationTests {
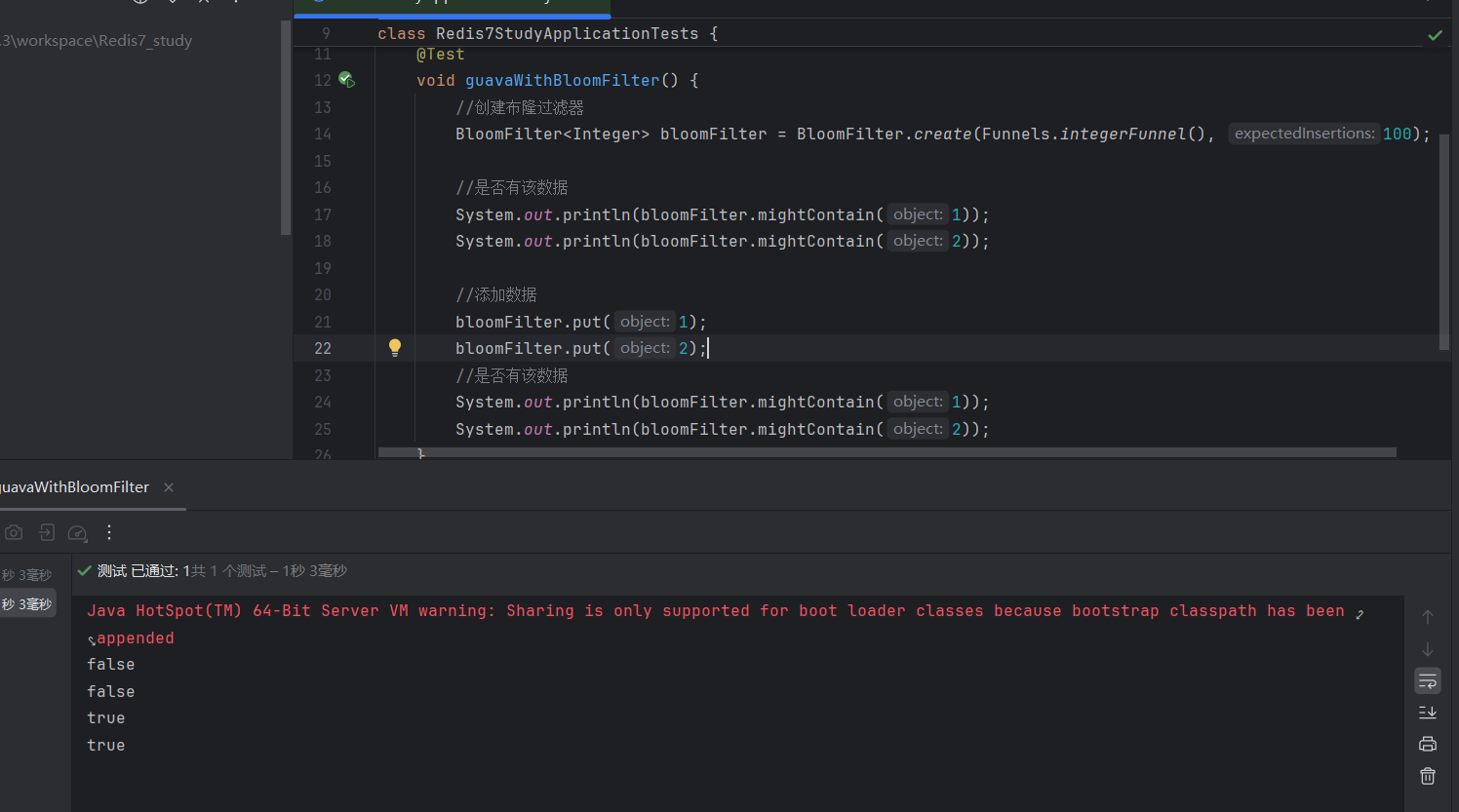
void guavaWithBloomFilter() {
//创建布隆过滤器
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 100);
//是否有该数据
System.out.println(bloomFilter.mightContain(1));
System.out.println(bloomFilter.mightContain(2));
//添加数据
bloomFilter.put(1);
bloomFilter.put(2);
//是否有该数据
System.out.println(bloomFilter.mightContain(1));
System.out.println(bloomFilter.mightContain(2));
}
}
实操:取样本100w数据,查查不在100w范围内,其他10w数据是否存在
GuavaBloomFilterServicepackage com.lazy.service;
import com.alibaba.google.common.hash.BloomFilter;
import com.alibaba.google.common.hash.Funnels;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
public class GuavaBloomFilterService {
public static final Integer _1W = 1000;
public static final Integer SIZE = 100 * _1W;//100w条数据
public static final double fpp = 0.03;//误判率
private final BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), SIZE, fpp);
public void guavaBloomFilter() {
//向布隆过滤器添加100w条数据
for (int i = 1; i <= SIZE ; i++) {
bloomFilter.put(i);
}
//取10万个不在过滤器里的值,看看有多少个会被认为在过滤器里
ArrayList<Integer> list = new ArrayList<>(10 * _1W);
for (int i = SIZE+1; i <= SIZE + (10 * _1W); i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
log.info("误判了:{}",i);
}
}
log.info("误判总数是:{}",list.size());
}
}GuavaBloomFilterControllerpackage com.lazy.controller;
import com.lazy.service.GuavaBloomFilterService;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
public class GuavaBloomFilterController {
private GuavaBloomFilterService guavaBloomFilterService;
public void guavaFilter() {
guavaBloomFilterService.guavaBloomFilter();
}
}结果

为什么误判率写0.03
Guava选择0.03作为默认误判率,本质是在内存开销(空间)与准确性(误报)间选取的工程最优解。用户可根据业务需求灵活调整,但若未显式指定,0.03能确保大多数场景下高效且可靠。hash函数占5个,效率更好,如果越精确,效率越慢!
FPP 哈希函数数量 内存占用 (百万元素) 适用场景 0.01 7 ~11.5 MB 高精度要求(如安全) 0.03 5 ~7.1 MB 通用默认(Guava) 0.1 4 ~4.8 MB 内存敏感场景 
布隆过滤器说明
缓存击穿
大量请求同时查询同一个key时,此时这个key正好失效,就会导致大量的请求都打到数据库上面去,简单来说就是热点key突然失效了,暴打MySQL
穿透和击穿,截然不同
危害
- 会造成某一时刻数据库请求量过大,压力剧增
- 需要知道热点key有哪些,防止击穿
解决
热点key失效
- 时间到了自然清除但还被访问到
- delete掉的key,刚巧又被访问
方案1
- 差异失效时间,对于访问频繁的热点key,干脆就不设置过期时间
方案2
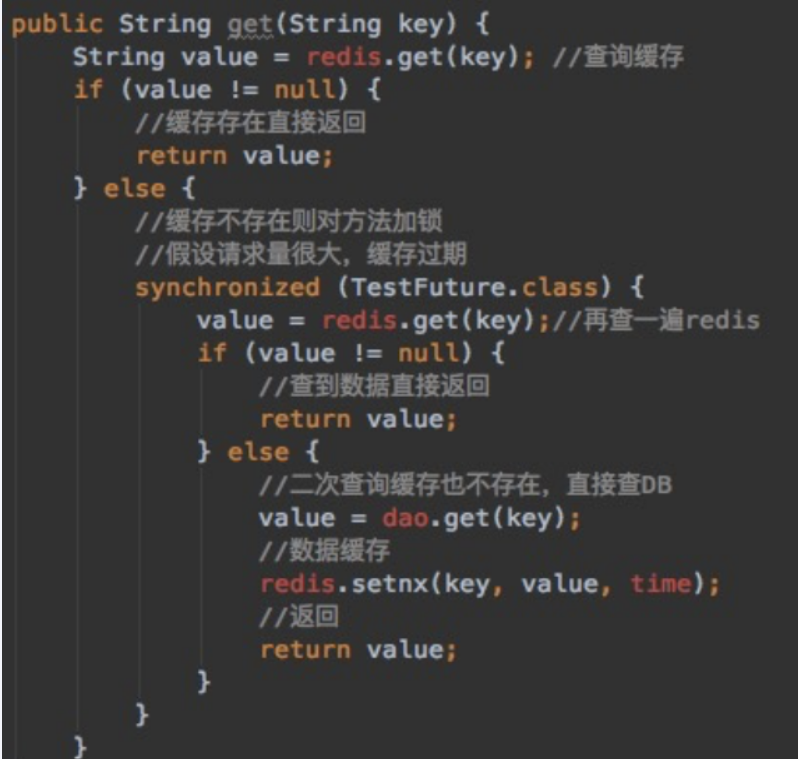
互斥更新,采用双检枷锁策略
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
案例
模拟高并发的天猫聚划算案例代码
| 步骤 | 说明 |
|---|---|
| 1 | 100%高并发,绝对不可以用mysql实现 |
| 2 | 先把mysql里面参加活动的数据抽取进redis,一般采用定时器扫描来决定上线活动还是下线取消。 |
| 3 | 支持分页功能,一页20条记录 |
redis数据类型使用list,因为zset更适合做排行榜
pom、yaml参考上面的
实体类
package com.lazy.pojo; |
service:采用定时器将参与聚划算活动的特价商品新增进redis中
package com.lazy.service; |
controller
package com.lazy.controller; |
bug和隐患
热点key突然失效导致可怕的缓存击穿
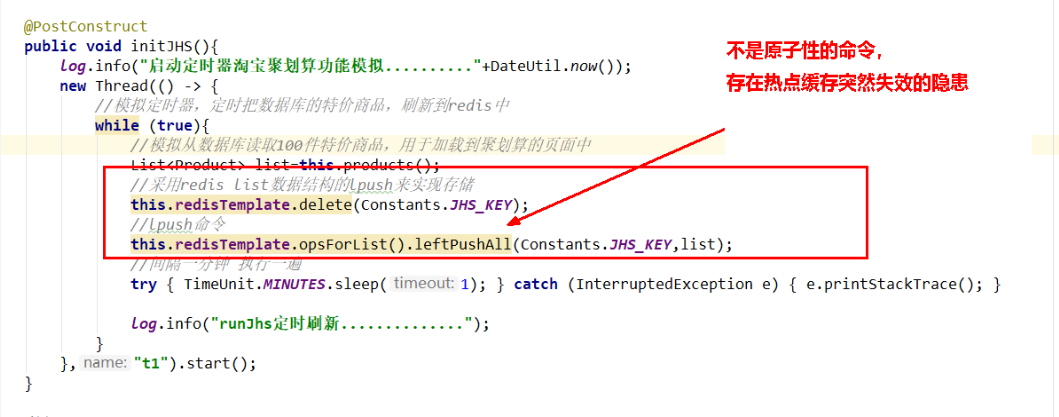
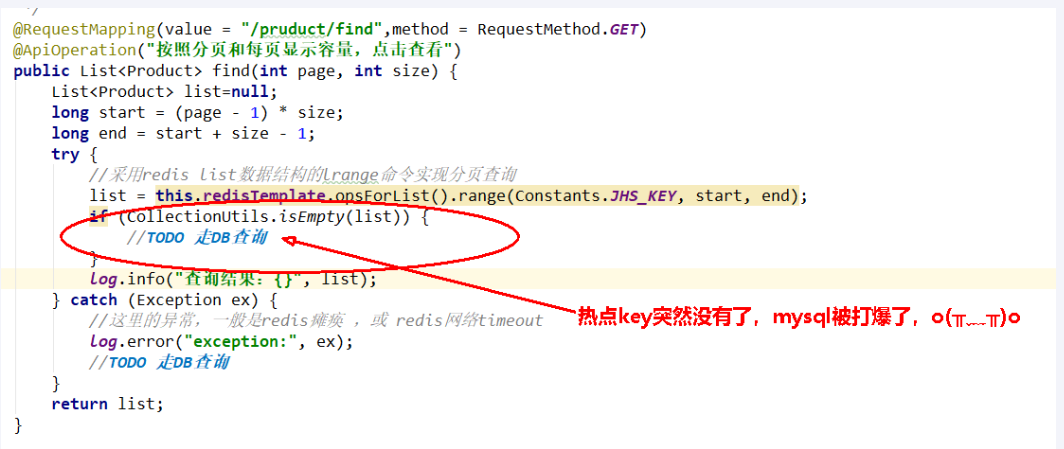
- delete命令执行的一瞬间有空隙,其他请求线程继续找Redis为null
- 打到了mysql,暴击….

最终目的
- 两条原子性还是其次,主要是防止key突然失效暴击mysql打爆系统
解决方案
采用双检枷锁策略
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
差异失效时间

我们采用差异失效时间来设置
更新JHSTaskService
package com.lazy.service; |
更新JHSProductController
package com.lazy.controller; |
总结


