
Redis为什么是单线程
这种问法其实并不严谨,为啥这么说呢?
Redis的版本很多3.x、4.x、6.x,版本不同架构也是不同的,不限定版本问是否单线程也不太严谨。
版本3.x ,最早版本,也就是大家口口相传的redis是单线程,阳哥2016年讲解的redis就是3.X的版本。
版本4.x,严格意义来说也不是单线程,而是负责处理客户端请求的线程是单线程,但是开始加了点多线程的东西(异步删除)。---貌似
2020年5月版本的6.0.x后及2022年出的7.0版本后,告别了大家印象中的单线程,用一种全新的多线程来解决问题。---实锤
几个里程碑的redis版本!
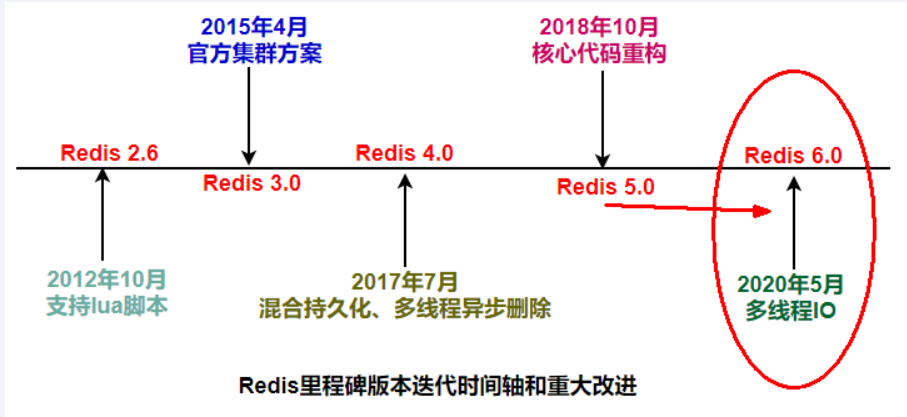
5.0版本是直接升级到6.0版本,对于这个激进的升级,Redis之父antirez表现得很有信心和兴奋,
所以第一时间发文来阐述6.0的一些重大功能"Redis 6.0.0 GA is out!"
当然,Redis7.0后版本更加厉害
- Redis是单线程
- 主要是指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。这也是Redis对外提供键值存储服务的主要流程。
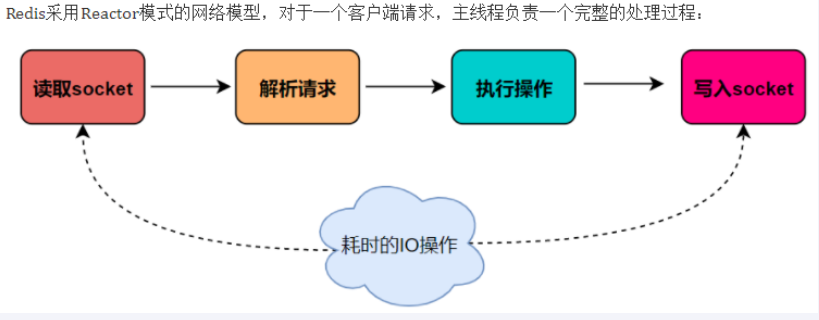
但Redis的其他功能,比如持久化RDB、AOF、异步删除、集群数据同步等等,其实是由额外的线程执行的。
Redis命令工作线程是单线程的,但是,整个Redis来说,是多线程的;
redis为什么是单线程的?
redis4之前一直都是单线程,redis4之后陆续加入多线程
简单来说,Redis4.0之前一直采用单线程的主要原因有以下三个:
- 使用单线程模型是 Redis 的开发和维护更简单,因为单线程模型方便开发和调试;
- 即使使用单线程模型也并发的处理多客户端的请求,主要使用的是IO多路复用和非阻塞IO;
- 对于Redis系统来说,主要的性能瓶颈是内存或者网络带宽而并非 CPU。
既然单线程那么好,为什么还要引入多线程特性?
正常情况下使用 del 指令可以很快的删除数据,而当被删除的 key 是一个非常大的对象时,例如时包含了成千上万个元素的 hash 集合时,那么 del 指令就会造成 Redis 主线程卡顿。
这就是redis3.x单线程时代最经典的故障,大key删除的头疼问题,
由于redis是单线程的,del bigKey .....
等待很久这个线程才会释放,类似加了一个synchronized锁,你可以想象高并发下,程序堵成什么样子?
如何解决?
比如当我(Redis)需要删除一个很大的数据时,因为是单线程原子命令操作,这就会导致 Redis 服务卡顿,
于是在 Redis 4.0 中就新增了多线程的模块,当然此版本中的多线程主要是为了解决删除数据效率比较低的问题的。
| unlink key |
|---|
| flushdb async |
| flushall async |
| 把删除工作交给了后台的小弟(子线程)异步来删除数据了。 |
因为Redis是单个主线程处理,redis之父antirez一直强调"Lazy Redis is better Redis".
而lazy free的本质就是把某些cost(主要时间复制度,占用主线程cpu时间片)较高删除操作,
从redis主线程剥离让bio子线程来处理,极大地减少主线阻塞时间。从而减少删除导致性能和稳定性问题。
redis7是否启用多线程?
Redis7将所有数据放在内存中,内存的响应时长大约为100纳秒,对于小数据包,Redis服务器可以处理8W到10W的QPS,
这也是Redis处理的极限了,对于80%的公司来说,单线程的Redis已经足够使用了。
在Redis6.0及7后,多线程机制默认是关闭的,如果需要使用多线程功能,需要在redis.conf中完成两个设置
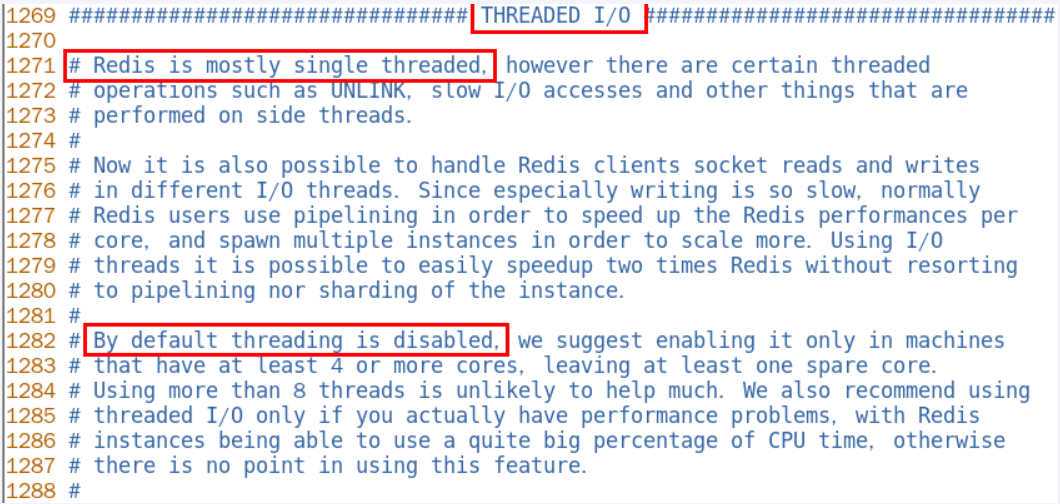
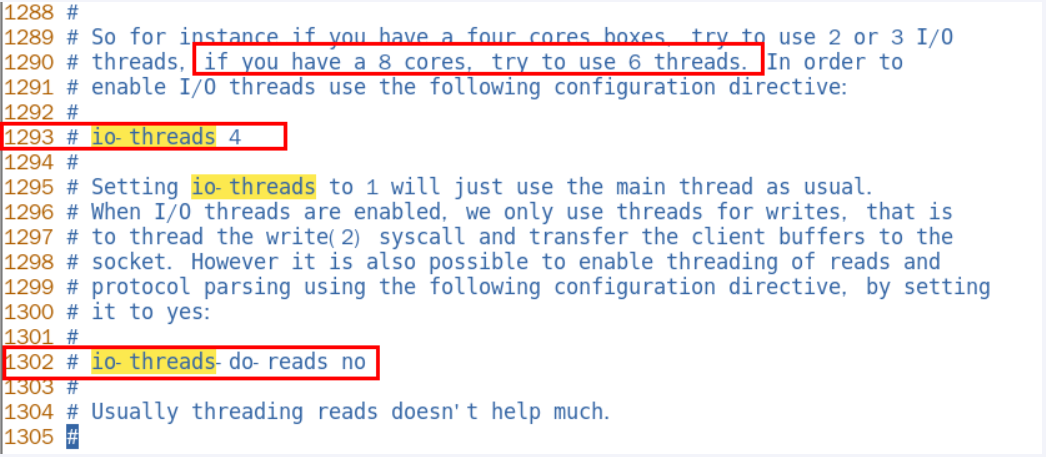
设置io-thread-do-reads配置项为yes,表示启动多线程。
设置线程个数。关于线程数的设置,官方的建议是如果为 4 核的 CPU,建议线程数设置为 2 或 3,如果为 8 核 CPU 建议线程数设置为 6,线程数一定要小于机器核数,线程数并不是越大越好。
BigKey
多大的key才算bigKey?
阿里云开发规范
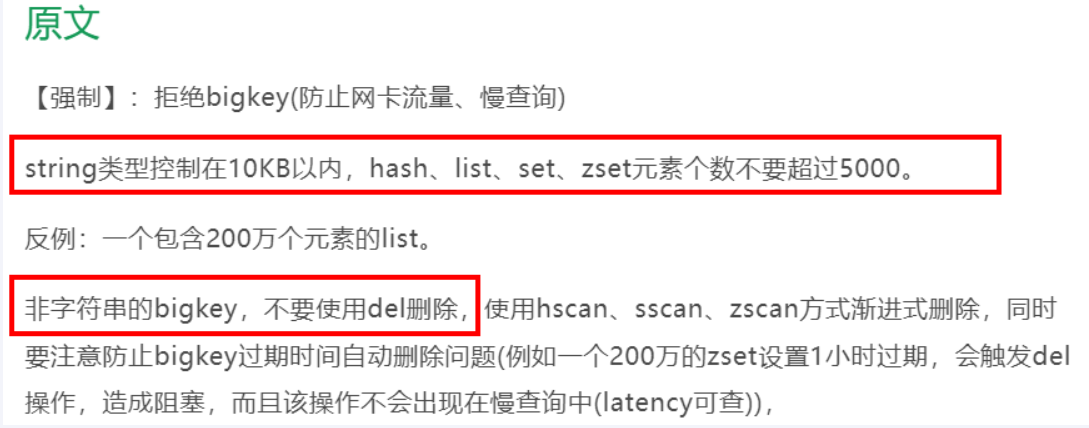
String和二级结构
- string是value,最大512MB但是>=10KB就是bigkey
- list、hash、set、和zset,个数超过5000就是bigkey
list
一个列表最多可以包含2的32次方-1个元素(4294967295,每个列表超过40亿个元素)
hash
Redis中每个hash可以存储2的32次方-1键值对(40多亿)
set
集合中最大的成员数2的32次方-1(4294967295,每个集合可存储40多亿个成员)
案例
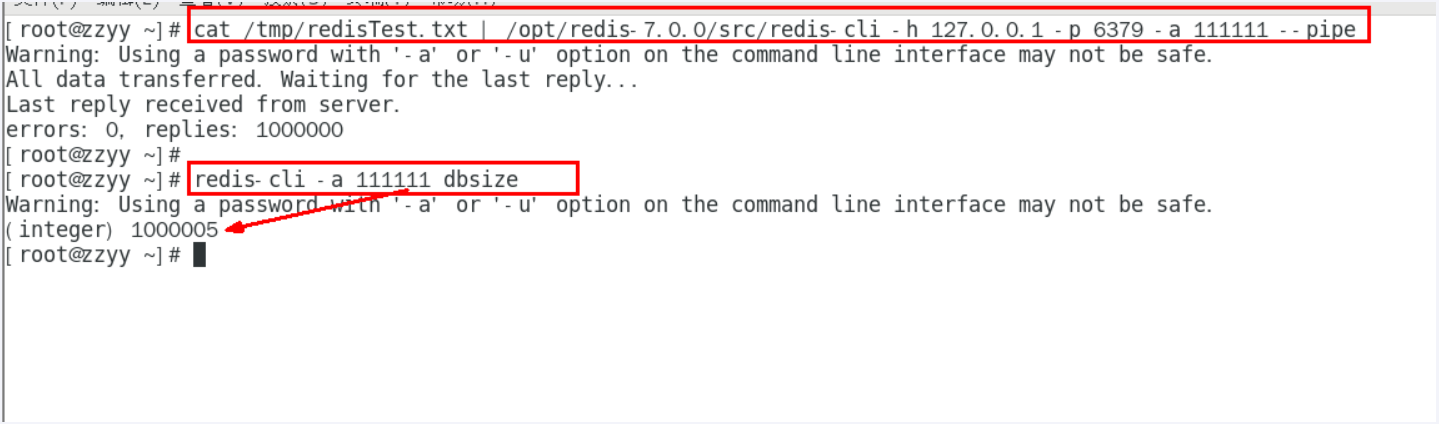
大批量往redis里插入100w测试数据key
在linux bash下面执行,插入100w
 c
c# 生成100W条redis批量设置kv的语句(key=kn,value=vn)写入到/tmp目录下的redisTest.txt文件中 for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> /tmp/redisTest.txt ;done;通过redis提供的管道
--pipe命令插入100w大批量数据结合自己机器的地址:
cat /tmp/redisTest.txt | /opt/redis-7.0.0/src/redis-cli -h 127.0.0.1 -p 6379 -a 111111 --pipe
多出来的5条,是之前阳哥自己的其它测试数据 ,参考阳哥机器硬件,100w数据插入redis花费5.8秒左右
使用keys *查询试试需要多少秒?
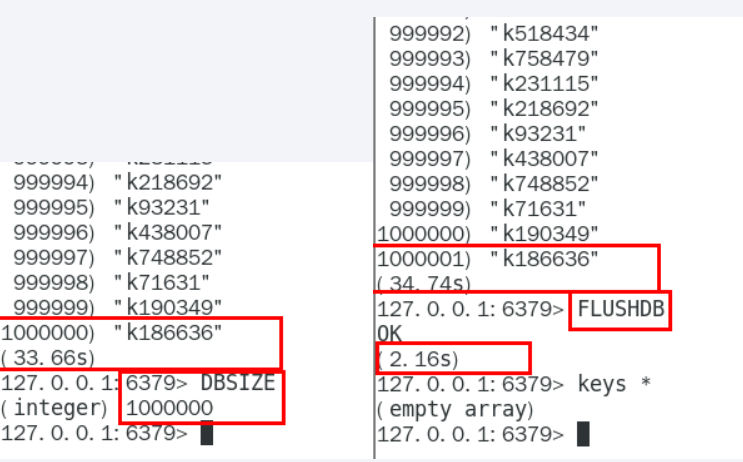
keys *这个指令有致命的弊端,在实际环境中最好不要使用

不用keys *避免卡顿,那用什么?
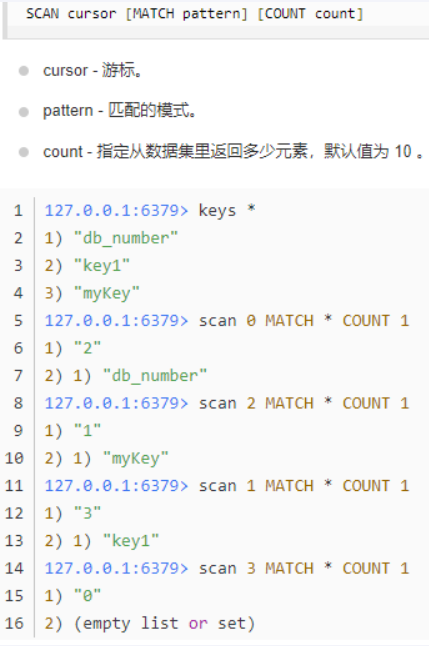
scan命令


特点:
SCAN 命令是一个基于游标的迭代器,每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
SCAN 返回一个包含两个元素的数组,
第一个元素是用于进行下一次迭代的新游标,
第二个元素则是一个数组, 这个数组中包含了所有被迭代的元素。如果新游标返回零表示迭代已结束。
SCAN的遍历顺序
非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
使用:
生产调优
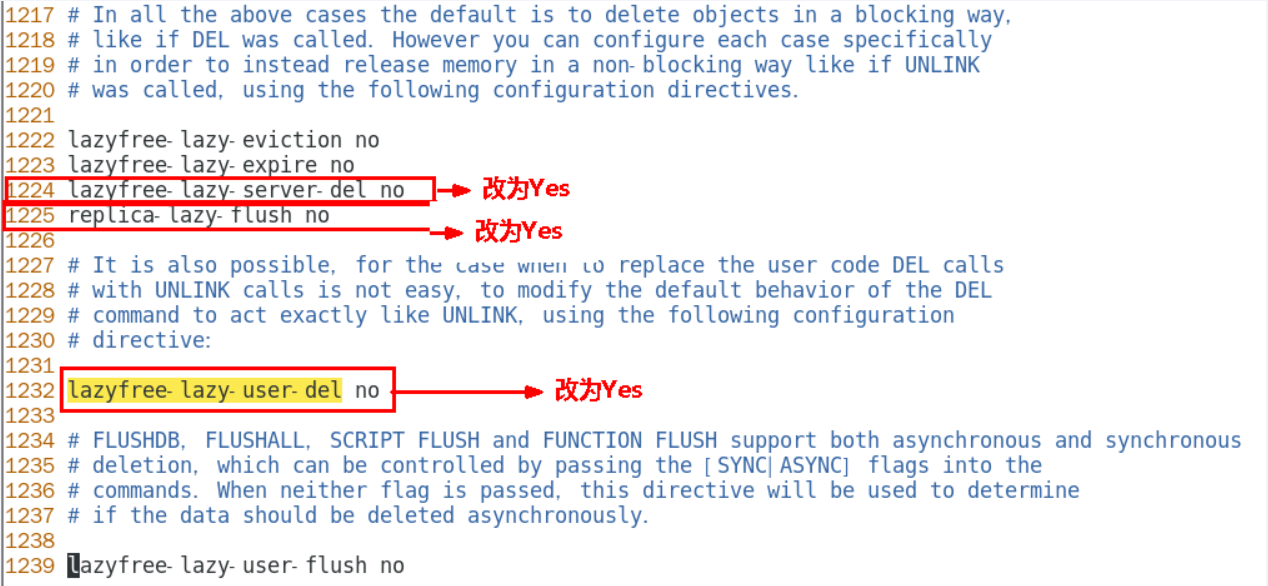
redis.conf文件LAZY FREEING相关说明
阻塞和非阻塞删除命令

优化配置
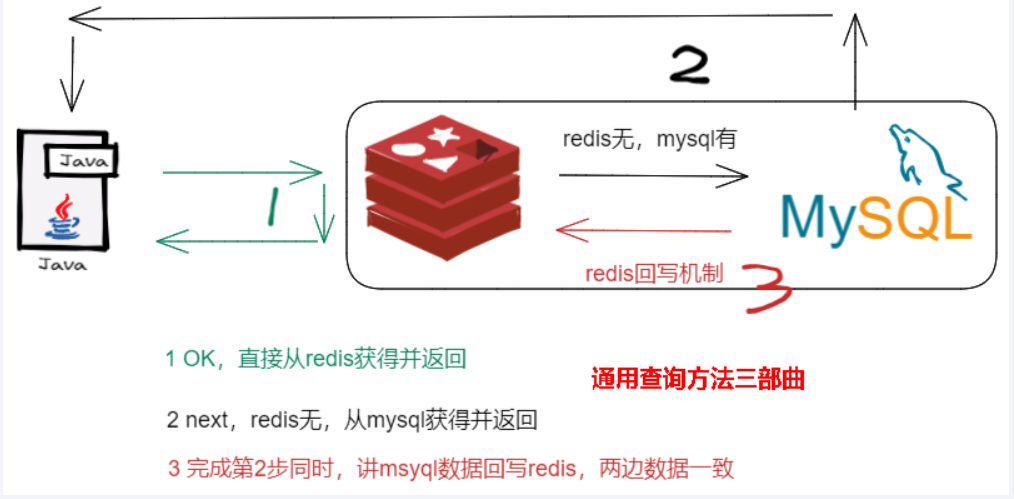
缓存双写一致性
如果redis中有数据:需要和数据库中的值相同
如果redis中无数据:数据库中的值要是最新值,且准备回写redis
缓存按照操作来分,细分2种
- 只读缓存
- 读写缓存
- 同步直写策略
- 写数据库也同步写redis缓存,缓存和数据库中的数据一致。
- 对于读写缓存来说,要想保证缓存和数据库中的数据一致,就要采用同步直写策略
- 异步缓写策略
- 正常业务运行中,mysql数据变动了,但是可以在业务上容许出现一定时间后才作用于redis,比如仓库、物流系统
- 异常情况出现了,不得不将失败的动作重新修补,有可能需要借助消息中间件,实现消息重写
- 同步直写策略
问题,上面业务逻辑你用java代码如何写?
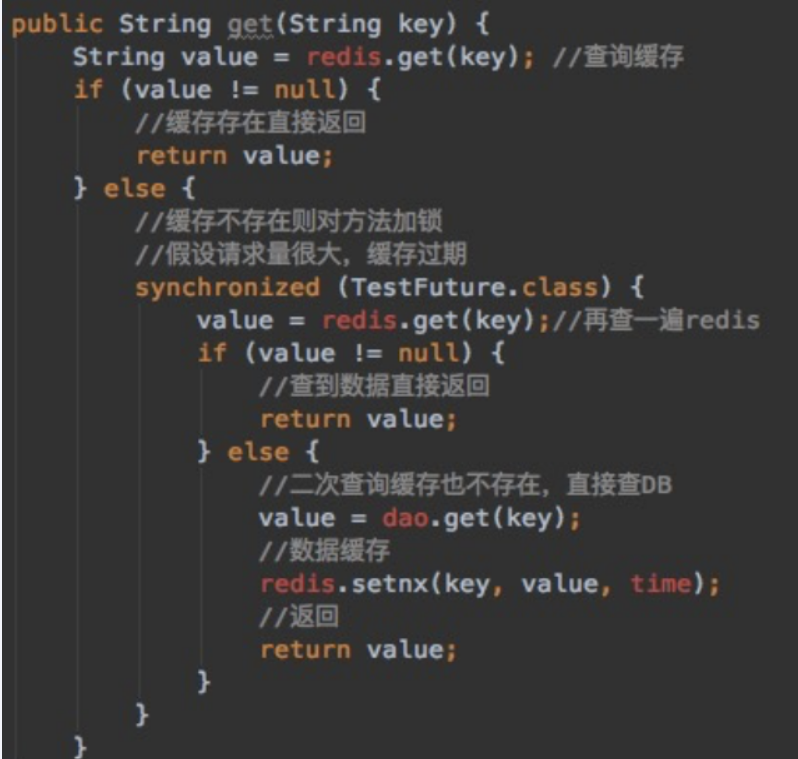
采用双检加锁策略
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。
后面的线程进来发现已经有缓存了,就直接走缓存。
@Service
@Slf4j
public class UserService {
public static final String CACHE_KEY_USER = "user:";
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate redisTemplate;
/**
* 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行
* @param id
* @return
*/
public User findUserById(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
{
//2 redis里面无,继续查询mysql
user = userMapper.selectByPrimaryKey(id);
if(user == null)
{
//3.1 redis+mysql 都无数据
//你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redis
return user;
}else{
//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key,user);
}
}
return user;
}
/**
* 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。
* @param id
* @return
*/
public User findUserById2(Integer id)
{
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql,
// 第1次查询redis,加锁前
user = (User) redisTemplate.opsForValue().get(key);
if(user == null) {
//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class){
//第2次查询redis,加锁后
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null) {
//4 查询mysql拿数据(mysql默认有数据)
user = userMapper.selectByPrimaryKey(id);
if (user == null) {
return null;
}else{
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
}
}
}
}
return user;
}
}数据库和缓存一致性的几种更新策略
目的:达到最终一致性
给缓存设置过期时间,定期清理缓存并回写,是保证最终一致性的解决方案。
我们可以对存入缓存的数据设置过期时间,所有的 写操作以数据库为准 ,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记,要以mysql的数据库写入库为准。
上述方案和后续落地案例是调研后的主流+成熟的做法,但是考虑到各个公司业务系统的差距,
不是100%绝对正确,不保证绝对适配全部情况,请同学们自行酌情选择打法,合适自己的最好。
可以停机的情况
- 挂牌报错,凌晨升级,温馨提示,服务降级
- 单线程,这样重量级的数据操作最好不要多线程
4种更新策略
先更新数据库,在更新缓存
异常问题1
- 先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。
- 先更新mysql修改为99成功,然后更新redis。
- 此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100 。
- 上述发生,会让数据库里面和缓存redis里面数据不一致,读到redis脏数据
异常问题2
【先更新数据库,再更新缓存】,A、B两个线程发起调用
【正常逻辑】
1 A update mysql 100
2 A update redis 100
3 B update mysql 80
4 B update redis 80
【异常逻辑】多线程环境下,A、B两个线程有快有慢,有前有后有并行
1 A update mysql 100
3 B update mysql 80
4 B update redis 80
2 A update redis 100
=============================
最终结果,mysql和redis数据不一致,o(╥﹏╥)o,
mysql80,redis100
先更新缓存,在更新数据库
不太推荐
业务上一般把mysql作为底单数据库(兜底),保证最后解释
异常问题
【先更新缓存,再更新数据库】,A、B两个线程发起调用
【正常逻辑】
1 A update redis 100
2 A update mysql 100
3 B update redis 80
4 B update mysql 80
【异常逻辑】多线程环境下,A、B两个线程有快有慢有并行
A update redis 100
B update redis 80
B update mysql 80
A update mysql 100
----mysql100,redis80
先删除缓存,在更新数据库
异常问题
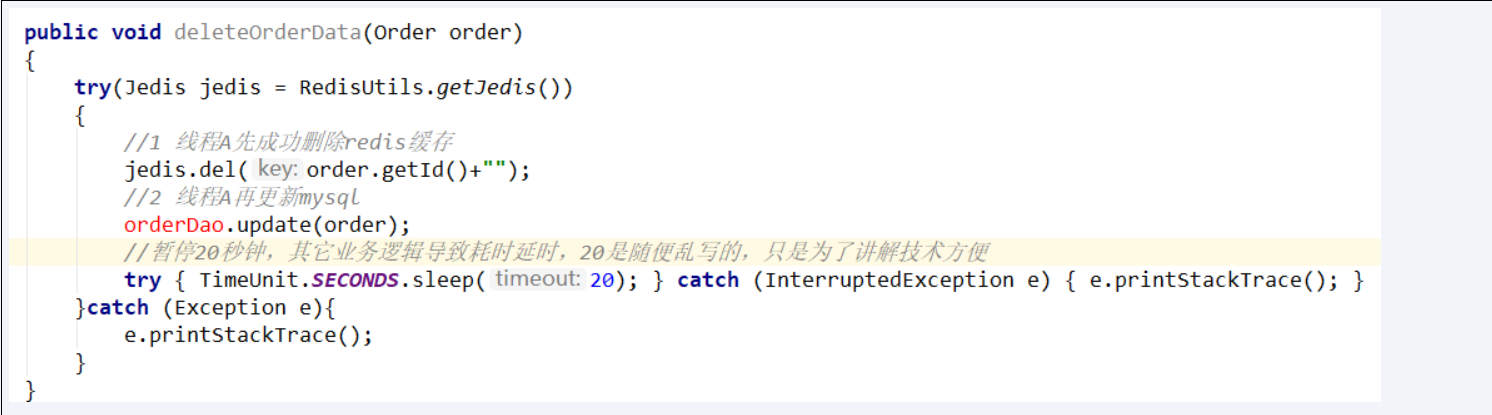
步骤分析1,先删除缓存,再更新数据库
A线程先成功删除了redis里面的数据,然后去更新mysql,此时mysql正在更新中,还没有结束。(比如网络延时)
B突然出现要来读取缓存数据。
20秒模拟网络延迟!
步骤分析2,先删除缓存,再更新数据库
此时redis里面的数据是空的,B线程来读取,先去读redis里数据(已经被A线程delete掉了),此处出来2个问题:
- B从mysql获得了旧值
- B线程发现redis里没有(缓存缺失)马上去mysql里面读取,从数据库里面读取来的是旧值。
B会把获得的旧值写回redis
获得旧值数据后返回前台并回写进redis(刚被A线程删除的旧数据有极大可能又被写回了)。
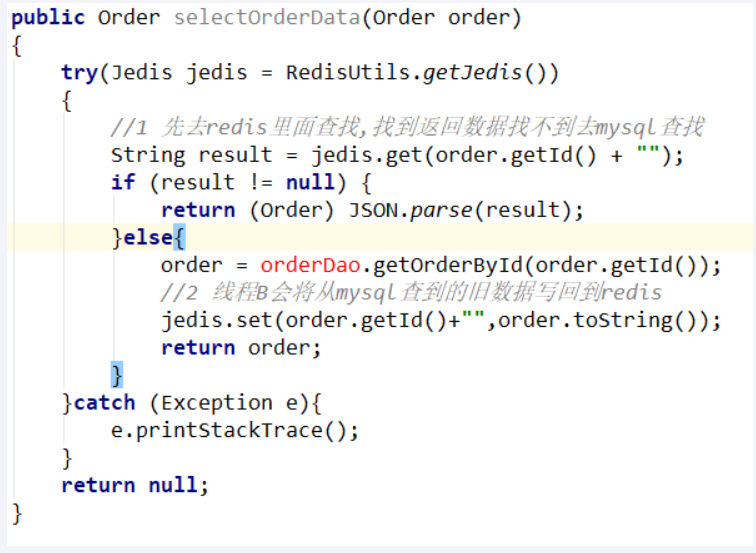
步骤分析3,先删除缓存,再更新数据库
A线程更新完mysql,发现redis里面的缓存是脏数据,A线程直接懵逼了,o(╥﹏╥)o
两个并发操作,一个是更新操作,另一个是查询操作,
A删除缓存后,B查询操作没有命中缓存,B先把老数据读出来后放到缓存中,然后A更新操作更新了数据库。
于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
总结流程:
请求A进行写操作,删除redis缓存后,工作正在进行中,更新mysql......A还么有彻底更新完mysql,还没commit
请求B开工查询,查询redis发现缓存不存在(被A从redis中删除了)
请求B继续,去数据库查询得到了mysql中的旧值(A还没有更新完)
请求B将旧值写回redis缓存
请求A将新值写入mysql数据库
上述情况就会导致不一致的情形出现。
时间 线程A 线程B 出现的问题 t1 请求A进行写操作,删除缓存成功后,工作正在mysql进行中...... t2 1 缓存中读取不到,立刻读mysql,由于A还没有对mysql更新完,读到的是旧值 2 还把从mysql读取的旧值,写回了redis 1 A还没有更新完mysql,导致B读到了旧值 2 线程B遵守回写机制,把旧值写回redis,导致其它请求读取的还是旧值,A白干了。 t3 A更新完mysql数据库的值,over redis是被B写回的旧值,mysql是被A更新的新值。出现了,数据不一致问题。 总结一下:
先删除缓存,再更新数据库 如果数据库更新失败或超时或返回不及时,导致B线程请求访问缓存时发现redis里面没数据,缓存缺失,B再去读取mysql时,从数据库中读取到旧值,还写回redis,导致A白干了,o(╥﹏╥)o
解决方案
采用延时双删策略
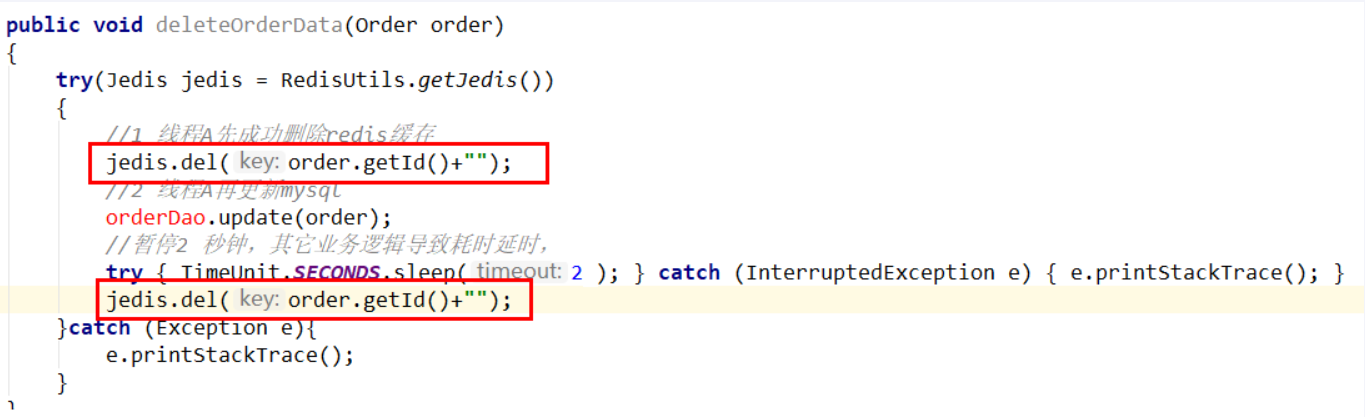

先更新数据库,再删除缓存
异常问题
先更新数据库,再删除缓存
时间 线程A 线程B 出现的问题 t1 更新数据库中的值...... t2 缓存中立刻命中,此时B读取的是缓存旧值。 A还没有来得及删除缓存的值,导致B缓存命中读到旧值。 t3 更新缓存的数据,over 先更新数据库,再删除缓存 假如缓存删除失败或者来不及,导致请求再次访问redis时缓存命中,读取到的是缓存旧值。 解决方案
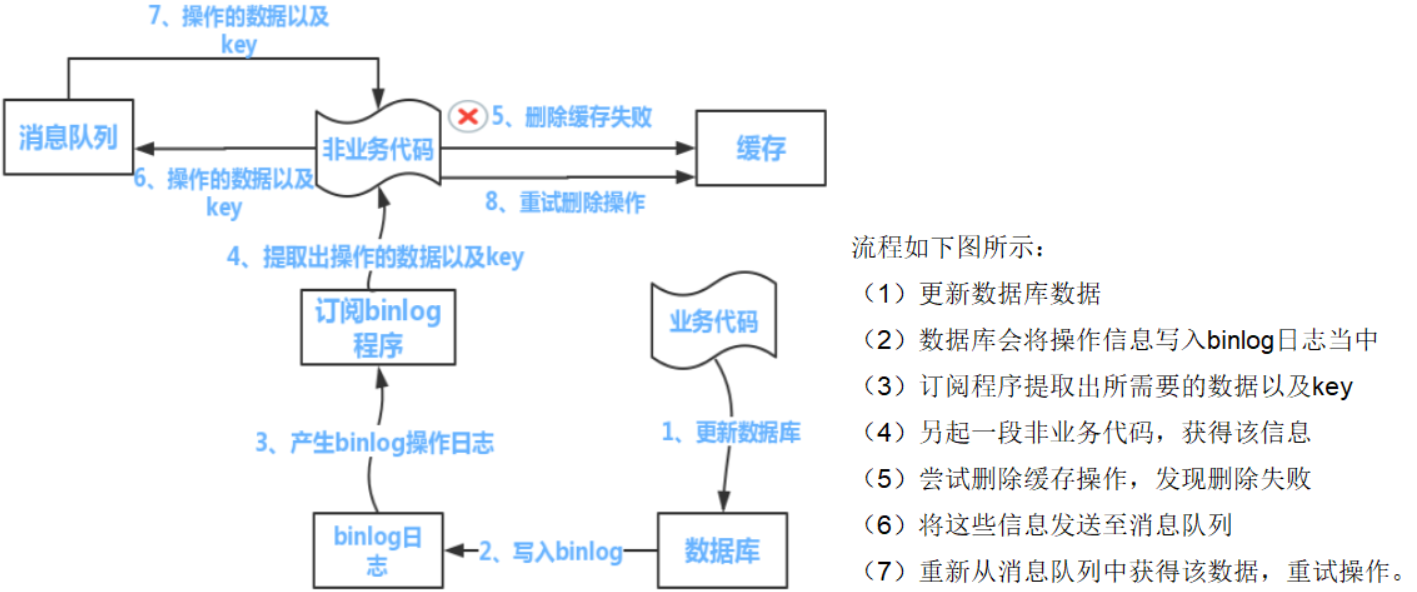
- 可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka/RabbitMQ等)。
- 当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
- 如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要再次进行重试
- 如果重试超过的一定次数后还是没有成功,我们就需要向业务层发送报错信息了,通知运维人员。
类似经典的分布式事务问题,只有一个权威答案
- 最终一致性
- 流量充值,先下发短信实际充值可能滞后5分钟,可以接受
- 电商发货,短信下发但是物流明天见
- 最终一致性
4种更新总结
建议:优先使用先更新数据库,再删除缓存的方案(先更库→后删存)。理由如下:
- 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力导致打满mysql。
- 如果业务应用中读取数据库和写缓存的时间不好估算,那么,延迟双删中的等待时间就不好设置。
多补充一句:如果使用先更新数据库,再删除缓存的方案
如果业务层要求必须读取一致性的数据,那么我们就需要在更新数据库时,先在Redis缓存客户端暂停并发读请求,等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性,这是理论可以达到的效果,但
实际,不推荐,因为真实生产环境中,分布式下很难做到实时一致性,一般都是最终一致性,请大家参考。
| 策略 | 高并发多线程条件下 | 问题 | 现象 | 解决方案 |
|---|---|---|---|---|
| 先删除redis缓存,再更新mysql | 无 | 缓存删除成功但数据库更新失败 | Java程序从数据库中读到旧值 | 再次更新数据库,重试 |
| 有 | 缓存删除成功但数据库更新中......有并发读请求 | 并发请求从数据库读到旧值并回写到redis,导致后续都是从redis读取到旧值 | 延迟双删 | |
| 先更新mysql,再删除redis缓存 | 无 | 数据库更新成功,但缓存删除失败 | Java程序从redis中读到旧值 | 再次删除缓存,重试 |
| 有 | 数据库更新成功但缓存删除中......有并发读请求 | 并发请求从缓存读到旧值 | 等待redis删除完成,这段时间有数据不一致,短暂存在。 |
Canal
是什么?
- 主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
能干嘛?
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务cache刷新
- 带业务逻辑的增量数据处理
工作原理
传统MySQL主从复制工作原理
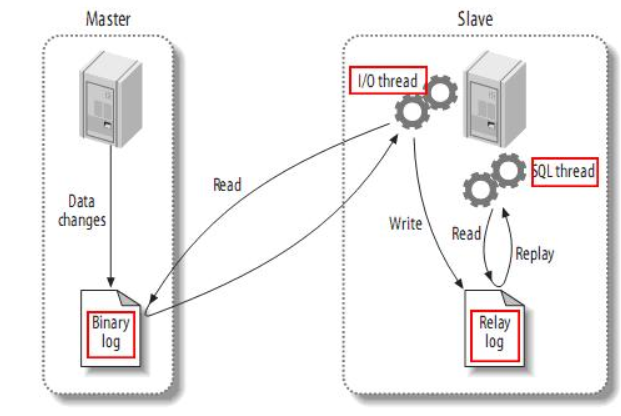
MySQL的主从复制将经过如下步骤:
- 当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中;
- salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变,
如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志;
- 同时 master 主服务器为每个 I/O Thread 启动一个dump Thread,用于向其发送二进制事件日志;
- slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
- salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;
- 最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒;
cana工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
canal 解析 binary log 对象(原始为 byte 流)
redis与mysql数据双写一致性案例
配置
mysql
查询mysql版本:
SELECT VERSION();
查看的主机二进制日志:
SHOW MASTER STATUS;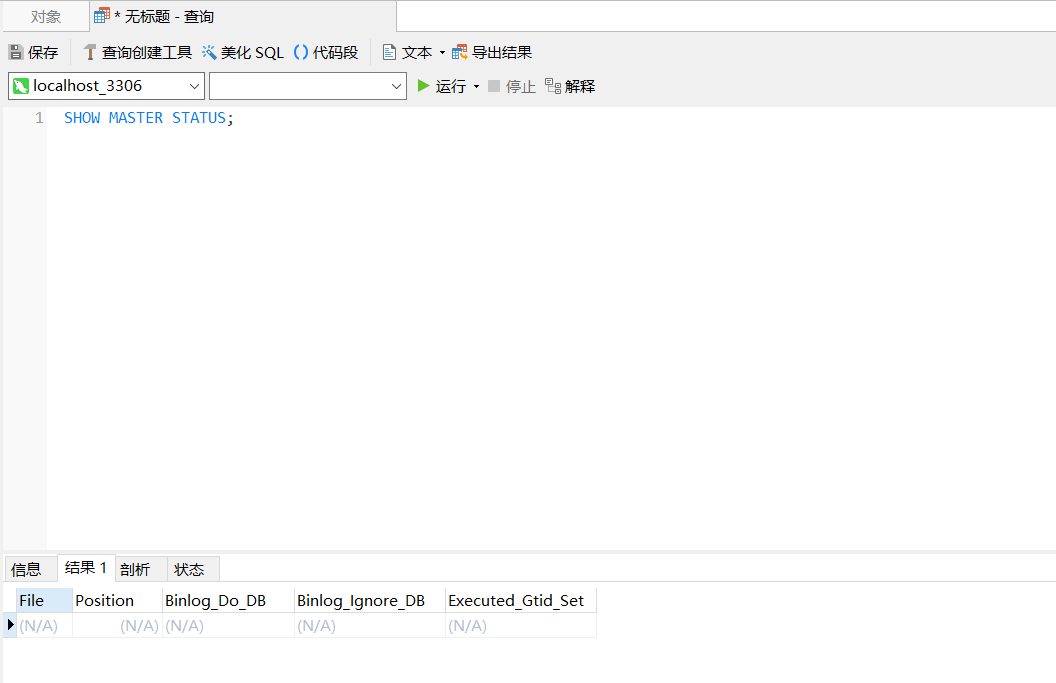
查看
SHOW VARIABLES LIKE 'log_bin';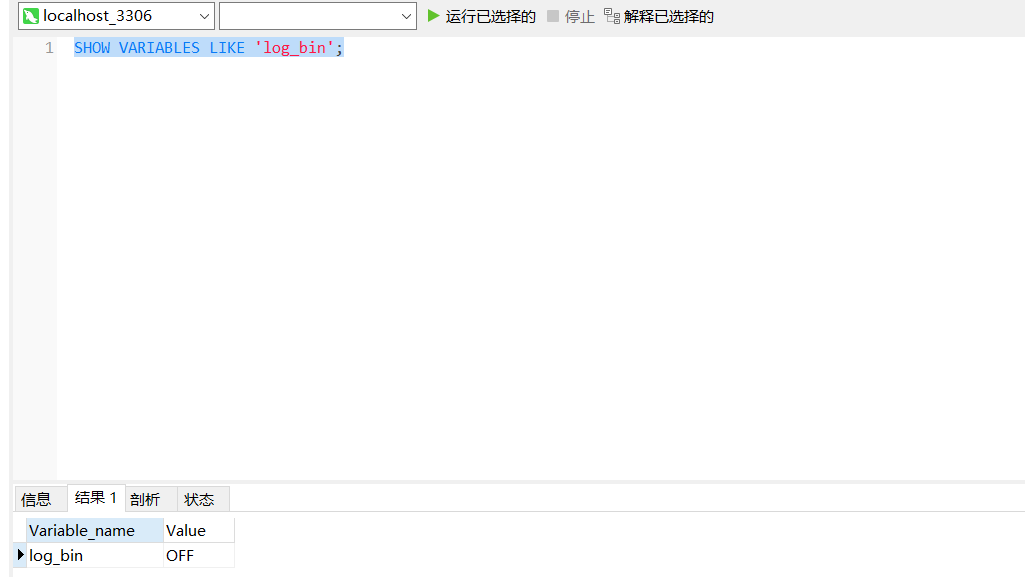
开启
MySQL的binlog写入功能最好提前备份
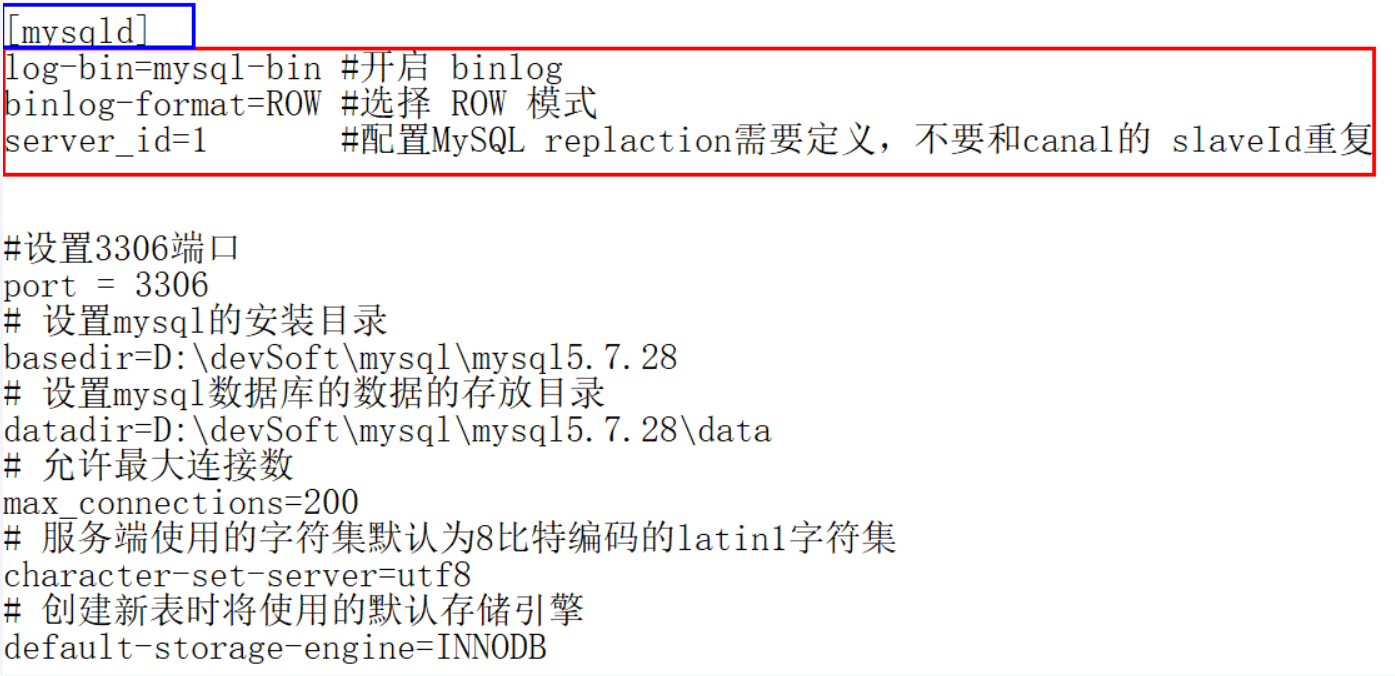
my.ini
window
my.inilinux
my.confsqllog-bin=mysql-bin #开启 binlog binlog-format=ROW #选择 ROW 模式 server_id=1 #配置MySQL replaction需要定义,不要和canal的 slaveId重复- ROW模式 除了记录sql语句之外,还会记录每个字段的变化情况,能够清楚的记录每行数据的变化历史,但会占用较多的空间。
- STATEMENT模式只记录了sql语句,但是没有记录上下文信息,在进行数据恢复的时候可能会导致数据的丢失情况;
- MIX模式比较灵活的记录,理论上说当遇到了表结构变更的时候,就会记录为statement模式。当遇到了数据更新或者删除情况下就会变为row模式;
重启
MySQL- 打开“服务”管理器:按 Win + R 键,输入 services.msc 并按回车。
- 找到 MySQL 服务(例如 MySQL80)。
- 右键点击该服务,选择“重新启动”。
再次查看
SHOW VARIABLES LIKE 'log_bin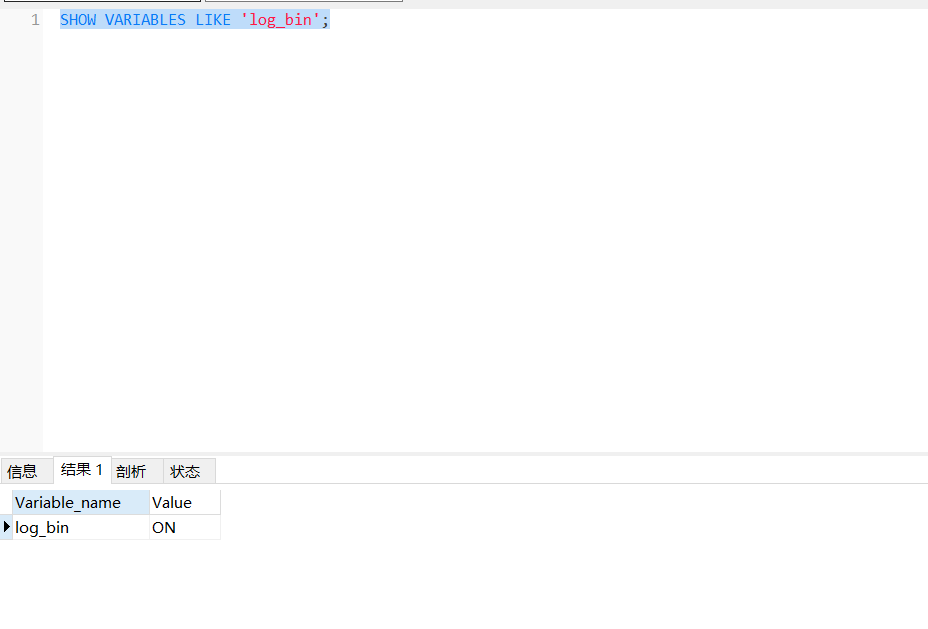
授权
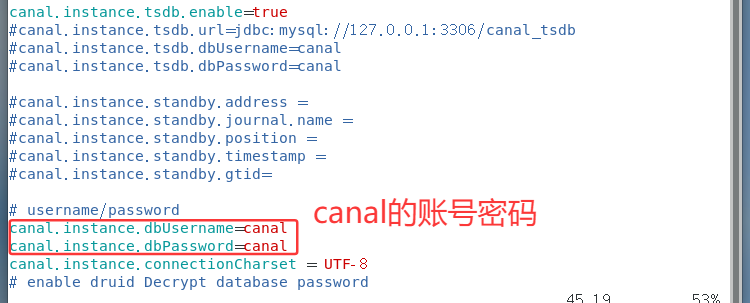
canal连接MySQL账号MySQL默认的用户在MySQL库的user表里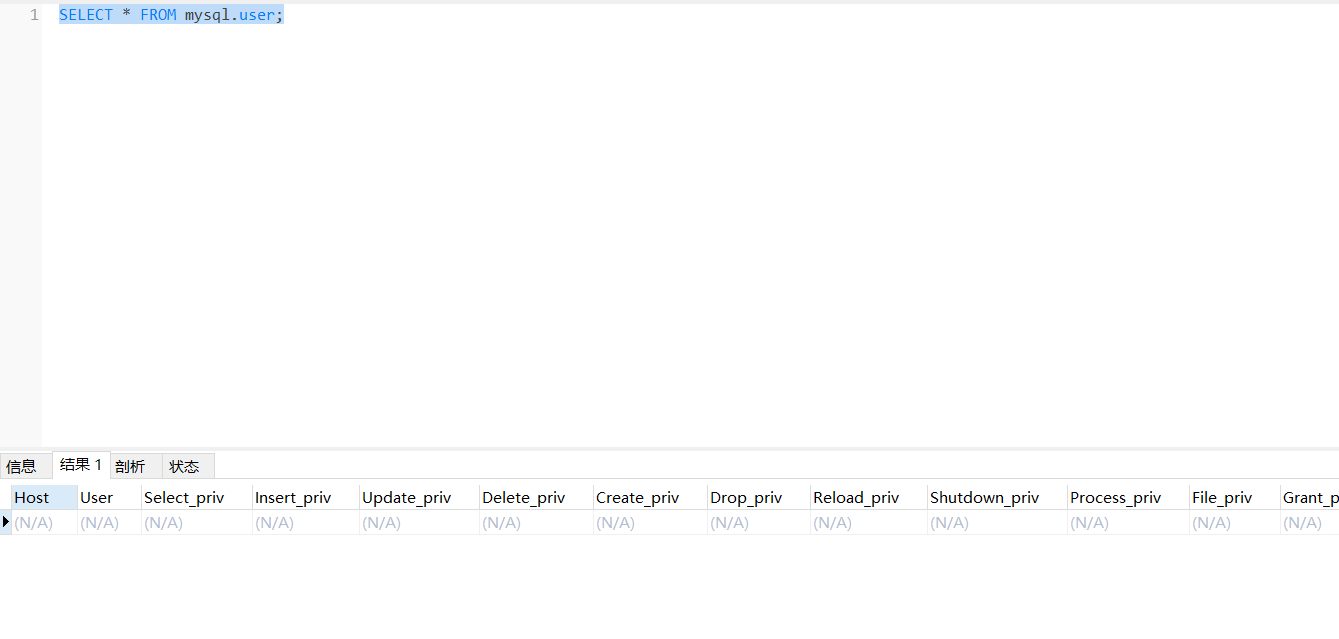
默认没有canal账户,在此处新建+授权
sql DROP USER IF EXISTS 'canal'@'%'; CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON . TO 'canal'@'%' IDENTIFIED BY 'canal';
FLUSH PRIVILEGES; SELECT * FROM mysql.user;如果提示`1290 - The MySQL server is running with the --skip-grant-tables option so it cannot execute this statement` sql FLUSH PRIVILEGES; DROP USER IF EXISTS 'canal'@'%'; CREATE USER 'canal'@'%' IDENTIFIED BY 'canal'; GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal'; FLUSH PRIVILEGES; SELECT * FROM mysql.user;
canal就添加好了!
canal服务端下载
https://github.com/alibaba/canal/releases/download/canal-1.1.8/canal.deployer-1.1.8.tar.gz
上传到
linux的某个位置我上传到根目录的
mycanal
解压文件
配置
instance.properties进入到
/mycanal/conf/example找到instance.properties使用vim编辑
instance.properties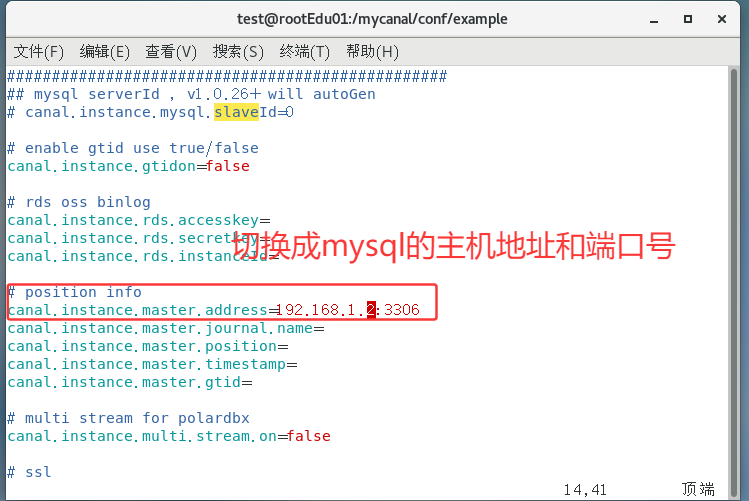
在
/mycanal/bin目录下执行,./startup.sh
查看
判断
canal启动是否成功查看server日志
/mycanal/logs/canal/canal.log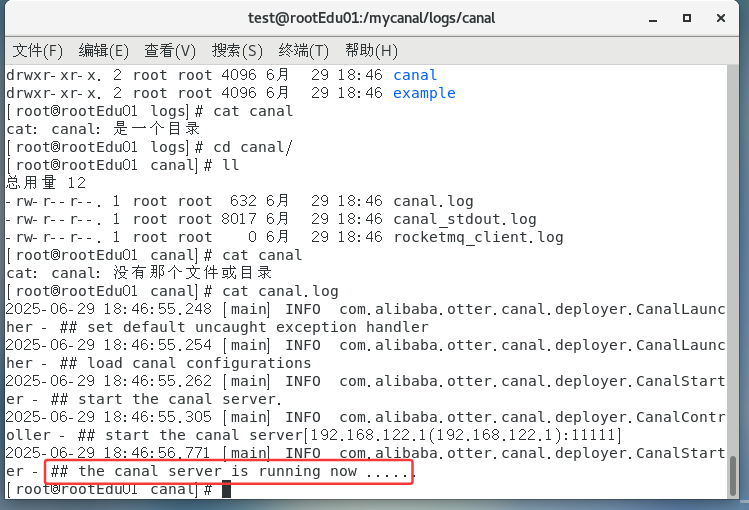
查看样例
example的日志/mycanal/logs/example/example.log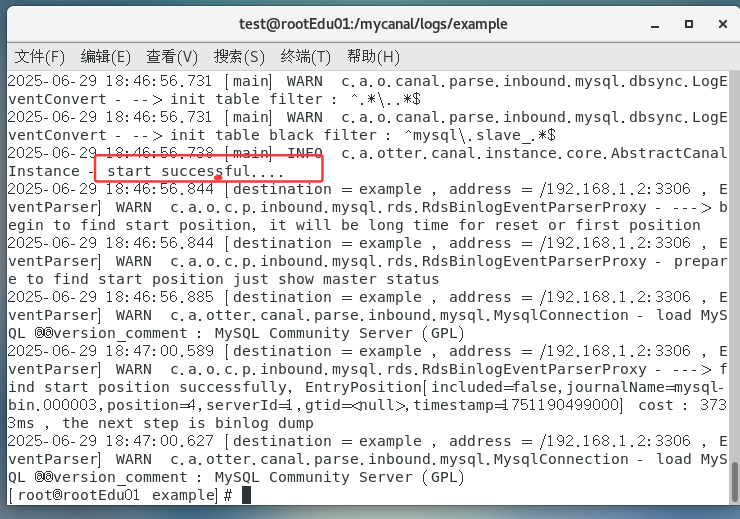
代码编写
pom
xml<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--jedis--> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>4.3.1</version> </dependency> <!-- lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <!-- redis --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency> <!--Mysql数据库驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> <!--SpringBoot集成druid连接池--> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency> <!--canal--> <dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.client</artifactId> <version>1.1.4</version> </dependency> </dependencies>yaml
yamlspring: datasource: type: com.alibaba.druid.pool.DruidDataSource username: root password: root url: jdbc:mysql://localhost:3306/db01?useUnicode=true&characterEncoding=utf-8&useSSL=false druid: test-while-idle: false application: name: Redis7_studyRedisUtlisjavapackage com.lazy.utlis; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; /** * @auther Lazy */ public class RedisUtils { public static final String REDIS_IP_ADDR = "192.168.0.13"; public static final String REDIS_pwd = "redis"; public static JedisPool jedisPool; static { JedisPoolConfig jedisPoolConfig=new JedisPoolConfig(); jedisPoolConfig.setMaxTotal(20); jedisPoolConfig.setMaxIdle(10); jedisPool=new JedisPool(jedisPoolConfig,REDIS_IP_ADDR,6379,10000,REDIS_pwd); } public static Jedis getJedis() throws Exception { if(null!=jedisPool){ return jedisPool.getResource(); } throw new Exception("Jedispool is not ok"); } }测试类
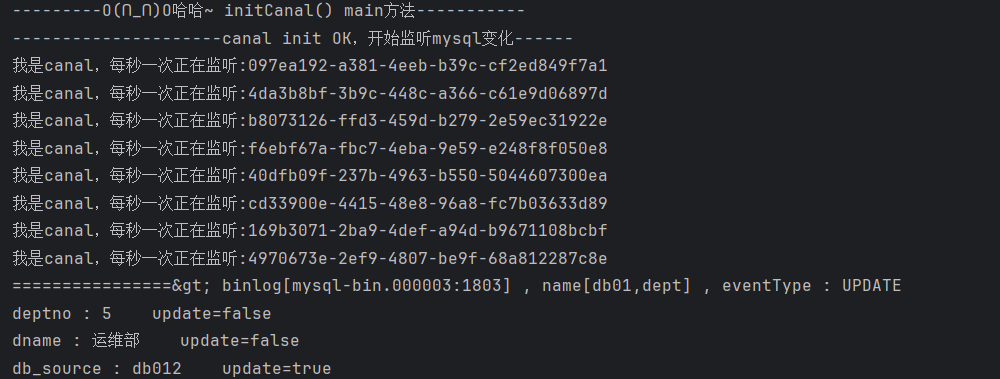
javapackage com.lazy.main; import com.alibaba.fastjson.JSONObject; import com.alibaba.otter.canal.client.CanalConnector; import com.alibaba.otter.canal.client.CanalConnectors; import com.alibaba.otter.canal.protocol.CanalEntry.*; import com.alibaba.otter.canal.protocol.Message; import com.lazy.utlis.RedisUtils; import redis.clients.jedis.Jedis; import java.net.InetSocketAddress; import java.util.List; import java.util.UUID; import java.util.concurrent.TimeUnit; /** * @author Lazy */ public class RedisCanalClientExample { public static final Integer _60SECONDS = 60; public static final String REDIS_IP_ADDR = "192.168.0.133"; private static void redisInsert(List<Column> columns) { JSONObject jsonObject = new JSONObject(); for (Column column : columns) { System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated()); jsonObject.put(column.getName(),column.getValue()); } if(columns.size() > 0) { try(Jedis jedis = RedisUtils.getJedis()) { jedis.set(columns.get(0).getValue(),jsonObject.toJSONString()); }catch (Exception e){ e.printStackTrace(); } } } private static void redisDelete(List<Column> columns) { JSONObject jsonObject = new JSONObject(); for (Column column : columns) { jsonObject.put(column.getName(),column.getValue()); } if(columns.size() > 0) { try(Jedis jedis = RedisUtils.getJedis()) { jedis.del(columns.get(0).getValue()); }catch (Exception e){ e.printStackTrace(); } } } private static void redisUpdate(List<Column> columns) { JSONObject jsonObject = new JSONObject(); for (Column column : columns) { System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated()); jsonObject.put(column.getName(),column.getValue()); } if(columns.size() > 0) { try(Jedis jedis = RedisUtils.getJedis()) { jedis.set(columns.get(0).getValue(),jsonObject.toJSONString()); System.out.println("---------update after: "+jedis.get(columns.get(0).getValue())); }catch (Exception e){ e.printStackTrace(); } } } public static void printEntry(List<Entry> entrys) { for (Entry entry : entrys) { if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) { continue; } RowChange rowChage = null; try { //获取变更的row数据 rowChage = RowChange.parseFrom(entry.getStoreValue()); } catch (Exception e) { throw new RuntimeException("ERROR ## parser of eromanga-event has an error,data:" + entry.toString(),e); } //获取变动类型 EventType eventType = rowChage.getEventType(); System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s", entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType)); for (RowData rowData : rowChage.getRowDatasList()) { if (eventType == EventType.INSERT) { redisInsert(rowData.getAfterColumnsList()); } else if (eventType == EventType.DELETE) { redisDelete(rowData.getBeforeColumnsList()); } else {//EventType.UPDATE redisUpdate(rowData.getAfterColumnsList()); } } } } public static void main(String[] args) { System.out.println("---------O(∩_∩)O哈哈~ initCanal() main方法-----------"); //================================= // 创建链接canal服务端 CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(REDIS_IP_ADDR, 11111), "example", "", ""); int batchSize = 1000; //空闲空转计数器 int emptyCount = 0; System.out.println("---------------------canal init OK,开始监听mysql变化------"); try { connector.connect(); //connector.subscribe(".*\\..*"); connector.subscribe("db01.dept"); connector.rollback(); int totalEmptyCount = 10 * _60SECONDS; while (emptyCount < totalEmptyCount) { System.out.println("我是canal,每秒一次正在监听:"+ UUID.randomUUID().toString()); Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据 long batchId = message.getId(); int size = message.getEntries().size(); if (batchId == -1 || size == 0) { emptyCount++; try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } else { //计数器重新置零 emptyCount = 0; printEntry(message.getEntries()); } connector.ack(batchId); // 提交确认 // connector.rollback(batchId); // 处理失败, 回滚数据 } System.out.println("已经监听了"+totalEmptyCount+"秒,无任何消息,请重启重试......"); } finally { connector.disconnect(); } } }效果
增

删

改
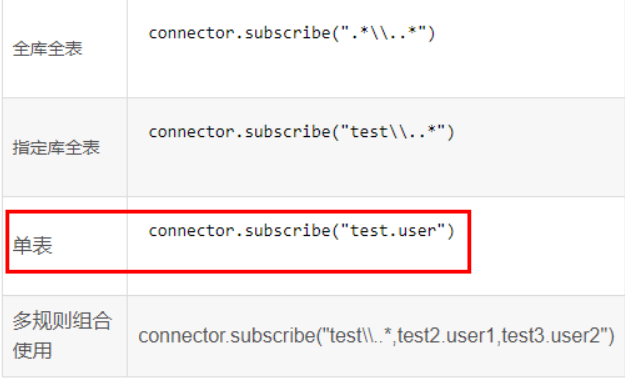
java程序下connector.subscribe配置的过滤正则
关闭资源代码简写
