
统计类型有哪些?
亿级系统中常见的四种统计
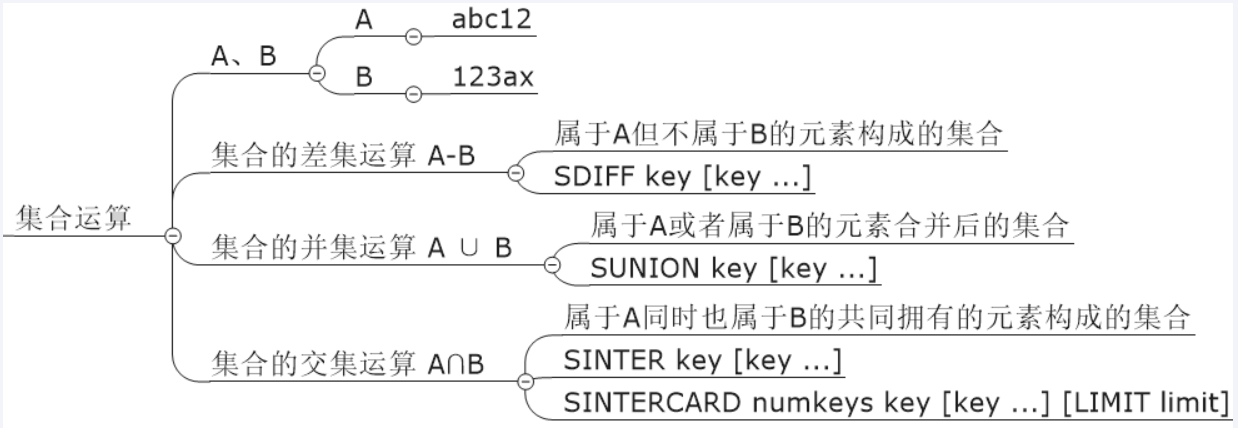
聚合统计
统计多个集合元素的聚合结果,就是前面的交集差集等集合统计
排序统计(zset)
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议使用ZSet
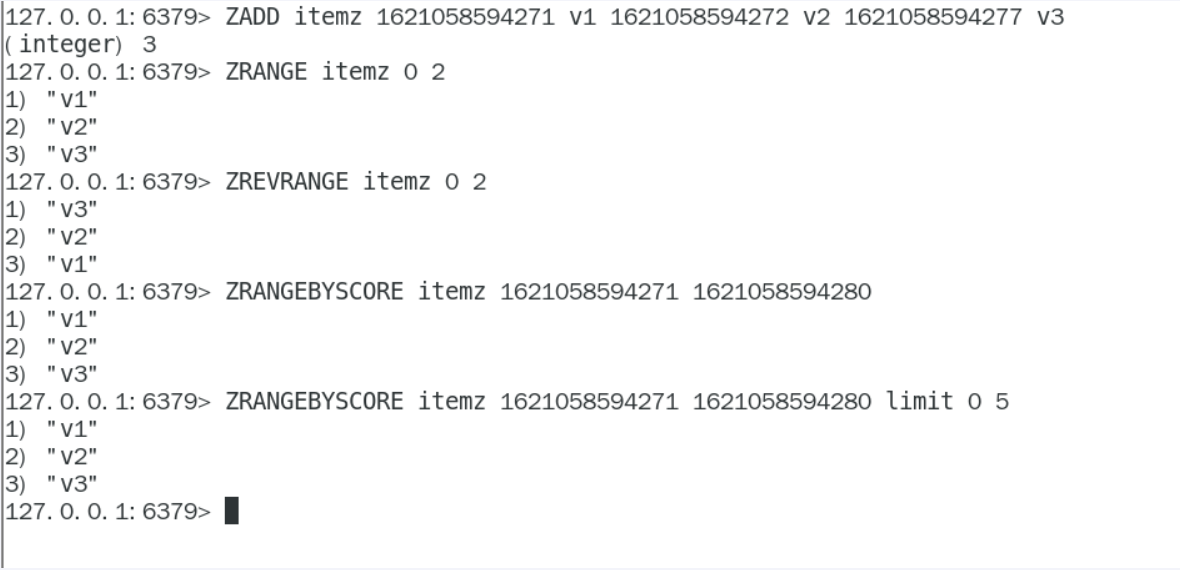
因为可以使用分页,正反排序
二值统计(bitmap)
集合元素的取值就只有0和1两种,在钉钉上班签到打开的场景中,我们只用记录有签到(1)和没签到(0)
基数统计(hyperloglog)
指 统计一个集合不重复元素个数
HyperLogLog
名词解释
什么是
UV?- Unique Visitor,独立访客,一般理解为客户端
IP - 需要去重考虑,例如一个人一天访问了10次网站,一天的
UV就是1
- Unique Visitor,独立访客,一般理解为客户端
什么是
PV?- Page View,页面浏览量
- 不用去重,例如一个人一天访问了10次网站,一天的
PV就是10
什么是
DAU?Daily Active User
日活跃用户量
登录或者使用了某个产品的用户数(去重复登录的用户),避免恶意刷单
常用于反映网站,互联网应用或者网络游戏的运营情况
什么是
MAU?Monthly Active User
月活跃用户量
需求
很多计数类场景,比如 每日注册 IP 数、每日访问 IP 数、页面实时访问数 PV、访问用户数 UV等。
因为主要的目标高效、巨量地进行计数,所以对存储的数据的内容并不太关心。
也就是说它只能用于统计巨量数量,不太涉及具体的统计对象的内容和精准性。
统计单日一个页面的访问量(PV),单次访问就算一次。
统计单日一个页面的用户访问量(UV),即按照用户为维度计算,单个用户一天内多次访问也只算一次。
多个key的合并统计,某个门户网站的所有模块的PV聚合统计就是整个网站的总PV。
HyperLogLog是什么?
基数(HyperLogLog):是一种数据集,去重复后的真实个数
例如:
(全集)=2,4,6,8,77,39,4,8,10
去掉重复的内容
基数 = {2,4,6,8,77,39,10} = 7
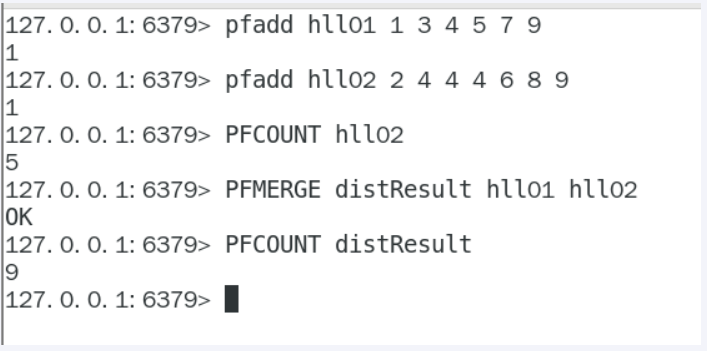
去重复统计功能的基数算法-就是HyperLogLog
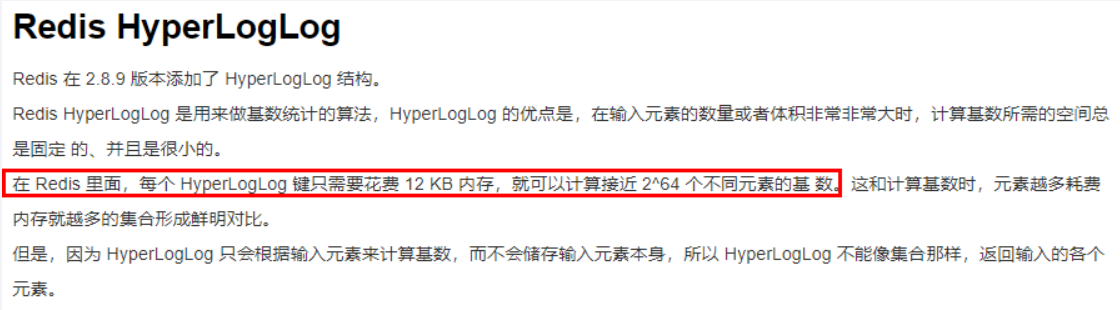
基数统计:用于统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算
一句话:去重脱水后的真实数据
基本命令:
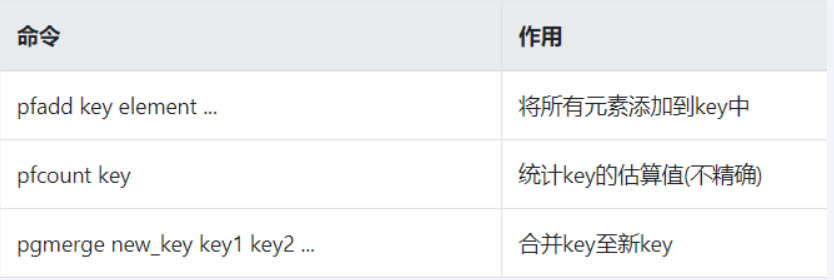
原理说明
- 只是进行不重复的基数统计,不是集合也不保存数据,只记录数量而不是具体内容
- 有误差
- HyperLogLog提供不精确的去重计数方案
- 牺牲准确率来换取时间,误差仅仅是0.81%左右
- 误差出处
HyperLogLog 案例
统计UV(需要去重)的访问量
HyperLogLogService
package com.lazy.service;
import jakarta.annotation.PostConstruct;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.Random;
@Slf4j
@Service
public class HyperLogLogService {
@Resource
private RedisTemplate<String,Object> redisTemplate;
/**
* PostConstruct:页面初始化完成之后立即执行该方法
*/
@PostConstruct
public void initIp() {
new Thread(() -> {
String ip;
for (int i = 0; i < 200; i++) {
Random random = new Random();
ip = random.nextInt(256) + "."
+ random.nextInt(256) + "."
+ random.nextInt(256) + "."
+ random.nextInt(256);
Long hll = redisTemplate.opsForHyperLogLog().add("hll",ip);
log.info("ip={},改ip访问首页的次数是{}",ip,hll);
//模拟用户访问
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
},"t1").start();
}
public Long uv(){
return redisTemplate.opsForHyperLogLog().size("hll");
}
}HyperLogLogController
package com.lazy.controller;
import com.lazy.service.HyperLogLogService;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HyperLogLogController {
@Resource
private HyperLogLogService hyperLogLogService;
@GetMapping("/uv")
public Long uv() {
return hyperLogLogService.uv();
}
}结果

GEO
经纬度
经度与纬度的合称组成一个坐标系统。又称为地理坐标系统,它是一种利用三度空间的球面来定义地球上的空间的球面坐标系统,能够标示地球上的任何一个位置。
经线和纬线
是人们为了在地球上确定位置和方向的,在地球仪和地图上画出来的,地面上并线。
和经线相垂直的线叫做纬线(纬线指示东西方向)。纬线是一条条长度不等的圆圈。最长的纬线就是赤道。
因为经线指示南北方向,所以经线又叫子午线。 国际上规定,把通过英国格林尼治天文台原址的经线叫做0°所以经线也叫本初子午线。在地球上经线指示南北方向,纬线指示东西方向。
东西半球分界线:东经160° 西经20°
经度和维度
经度(longitude):东经为正数,西经为负数。东西经
纬度(latitude):北纬为正数,南纬为负数。南北纬

命令
GEOADD添加经纬度坐标


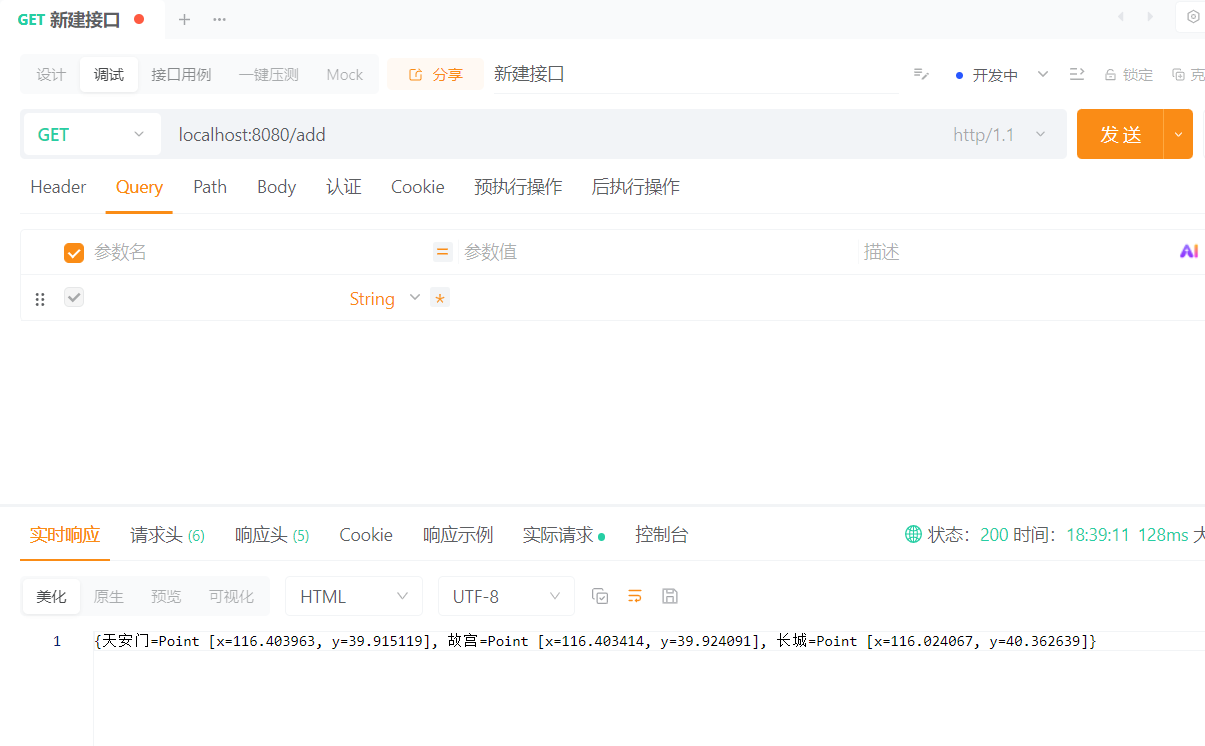
GEOADD city 116.403963 39.915119 "天安门" 116.403414 39.924091 "故宫" 116.024067 40.362639 "长城"
处理中文乱码
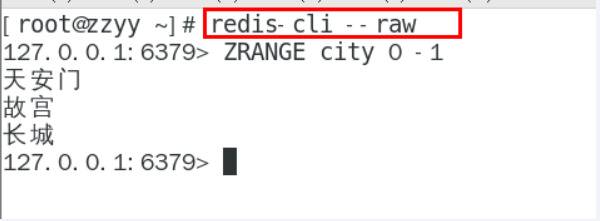
GEOPOS返回经纬度


GEOPOS city 天安门 故宫
GEOHASH返回坐标的geohash表示
geohash算法生成的base32编码值


GEOHASH city 天安门 故宫 长城
GEODIST两个位置之间的距离


GEODIST city 天安门 长城 km
后面参数是距离单位:
m 米
km 千米
ft 英尺
mi 英里
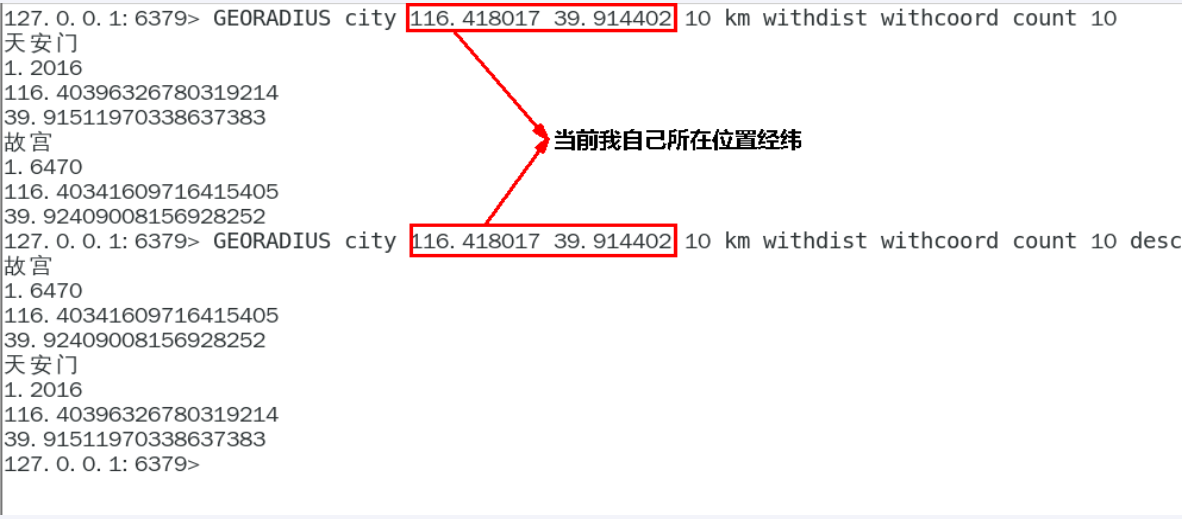
GEORADIUS以半径为中心,查找附近的XXX
georadius以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
GEORADIUS city 116.418017 39.914402 10 km withdist withcoord count 10 withhash desc
GEORADIUS city 116.418017 39.914402 10 km withdist withcoord count 10 desc
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
WITHCOORD: 将位置元素的经度和维度也一并返回。
WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大
COUNT 限定返回的记录数。
GEORADIUSBYMEMBER


案例
GEOService
package com.lazy.service;
import jakarta.annotation.Resource;
import org.springframework.data.geo.*;
import org.springframework.data.redis.connection.RedisGeoCommands;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
public class GEOService {
@Resource
private RedisTemplate redisTemplate;
private static final String CITY = "city";
/**
* 添加经纬度坐标
* @return String
*/
public String geoAdd() {
Map<String, Point> map = new HashMap<>();
map.put("天安门", new Point(116.403963, 39.915119));
map.put("故宫", new Point(116.403414, 39.924091));
map.put("长城", new Point(116.024067, 40.362639));
redisTemplate.opsForGeo().add(CITY, map);
return map.toString();
}
/**
* 根据名称获得经纬度的坐标
* @param member 地方名称
* @return Point
*/
public Point position(String member){
List<Point> pointList = redisTemplate.opsForGeo().position(CITY, member);
if (pointList != null) {
return pointList.get(0);
}
return null;
}
/**
* 根据名称获得 hash值
* @param member 地方名称
* @return String
*/
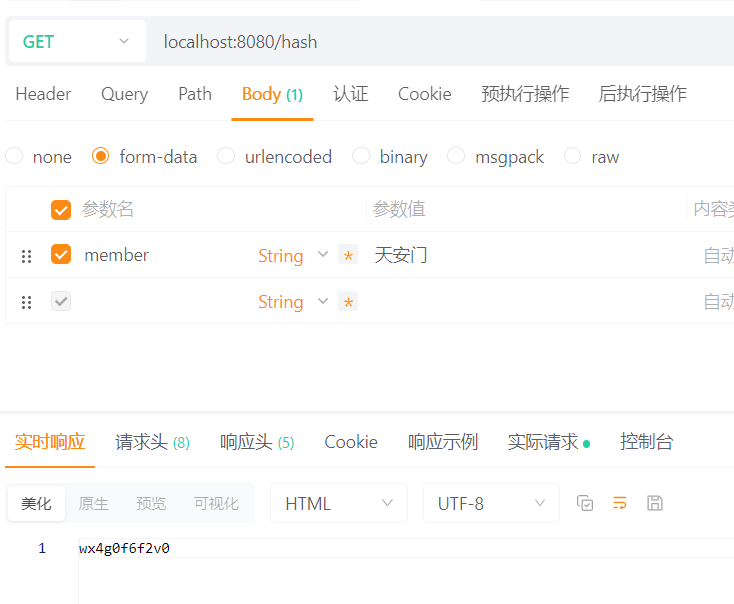
public String hash(String member){
List<String> listHash = redisTemplate.opsForGeo().hash(CITY, member);
if (listHash != null) {
return listHash.get(0);
}
return member;
}
/**
* 获得两个位置之间给定的距离公里
* @param member1 地方名称1
* @param member2 地方名称2
* @return Distance
*/
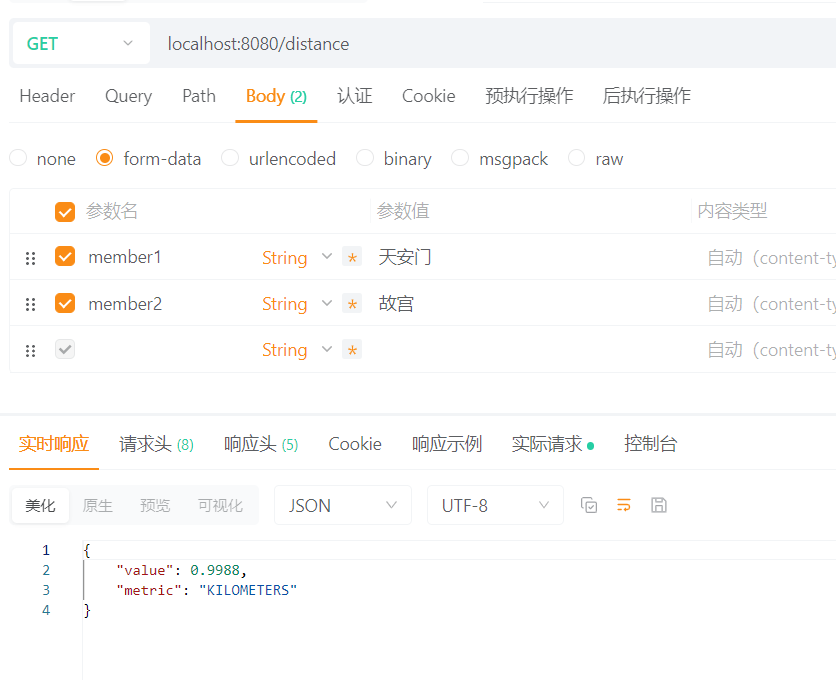
public Distance distance(String member1, String member2){
return redisTemplate.opsForGeo().distance(CITY, member1, member2, Metrics.KILOMETERS);
}
/**
* 通过经度,纬度查找附近的,北京王府井位置116.418017,39.914402
* @return GeoResults
*/
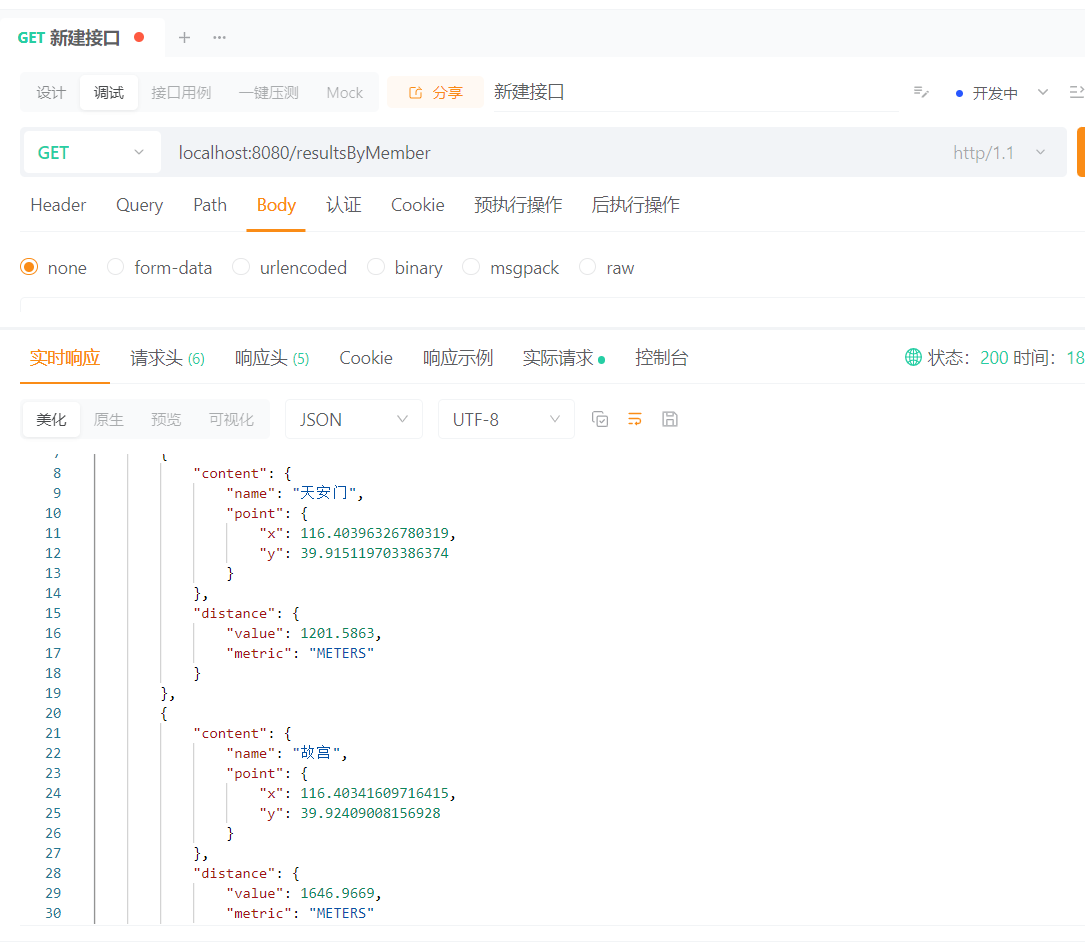
public GeoResults<RedisGeoCommands.GeoLocation<String>> resultsByMember(){
Circle circle = new Circle(116.418017, 39.914402, Metrics.KILOMETERS.getMultiplier());
//返回50条,升序
return redisTemplate.opsForGeo().radius(CITY, circle, RedisGeoCommands.GeoRadiusCommandArgs
.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(50));
}
}GEOController
package com.lazy.controller;
import com.lazy.service.GEOService;
import jakarta.annotation.Resource;
import jakarta.websocket.server.PathParam;
import org.springframework.data.geo.*;
import org.springframework.data.redis.connection.RedisGeoCommands;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class GEOController {
@Resource
private GEOService geoService;
@GetMapping("/add")
public String geoAdd() {
return geoService.geoAdd();
}
@GetMapping("/position")
public Point position(@PathParam("member") String member){
return geoService.position(member);
}
@GetMapping("/hash")
public String hash(@PathParam("member")String member){
return geoService.hash(member);
}
@GetMapping("/distance")
public Distance distance(@PathParam("member1")String member1,@PathParam("member2") String member2){
return geoService.distance(member1, member2);
}
@GetMapping("/resultsByMember")
public GeoResults<RedisGeoCommands.GeoLocation<String>> resultsByMember(){
return geoService.resultsByMember();
}
}效果

bitmap
由0和1状态表现的二进制的bit数组
- 能干嘛
- 用于状态统计
命令
setbit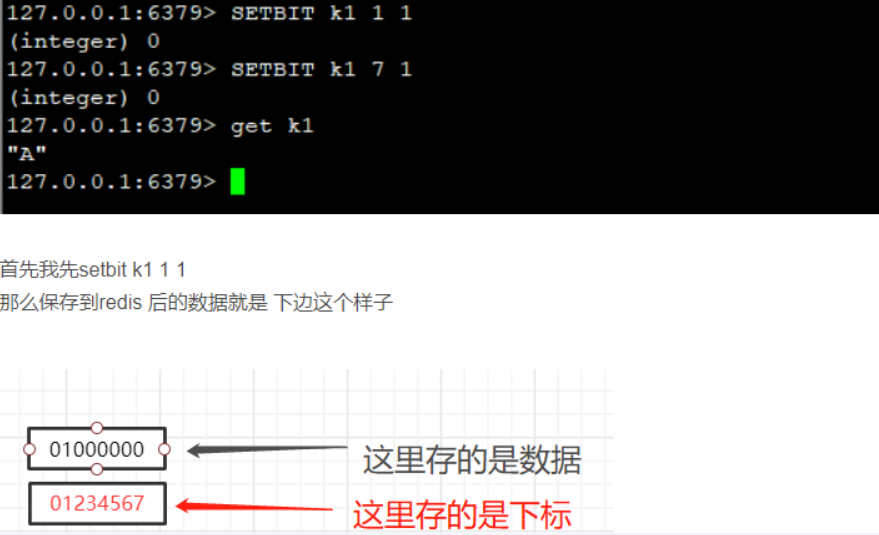
setbit 键 偏移位 只能零或者1
Bitmap的偏移量是从零开始算的
gitbit key offsetsetbit和gitbit案例说明- 按天
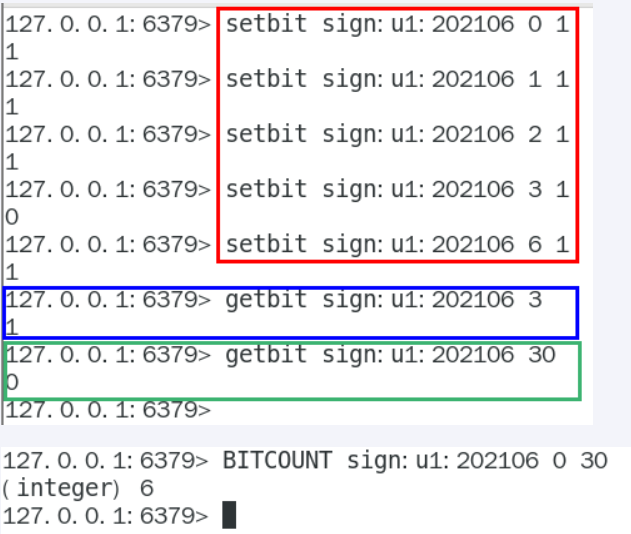
按照年
按年去存储一个用户的签到情况,365 天只需要 365 / 8 ≈ 46 Byte,1000W 用户量一年也只需要 44 MB 就足够了。
假如是亿级的系统,
每天使用1个1亿位的Bitmap约占12MB的内存(10^8/8/1024/1024),10天的Bitmap的内存开销约为120MB,内存压力不算太高。在实际使用时,最好对Bitmap设置过期时间,让Redis自动删除不再需要的签到记录以节省内存开销。
strlen:统计字节数占用多少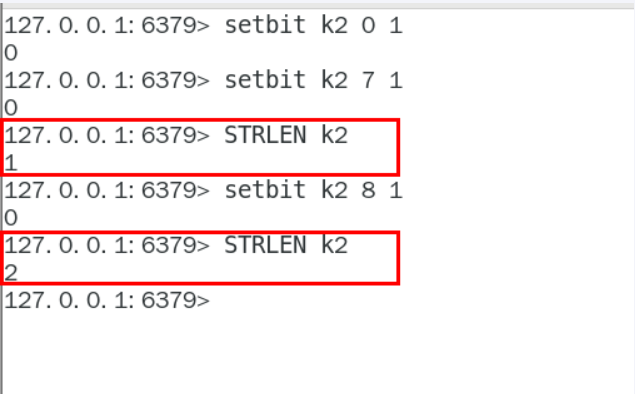
- 不是字符串长度而是占据几个字节,超过8位后自己按照8位一组一byte再扩容
bitcount全部键里面含有1的有多少个?
一年365天,全年天天登陆占用多少字节
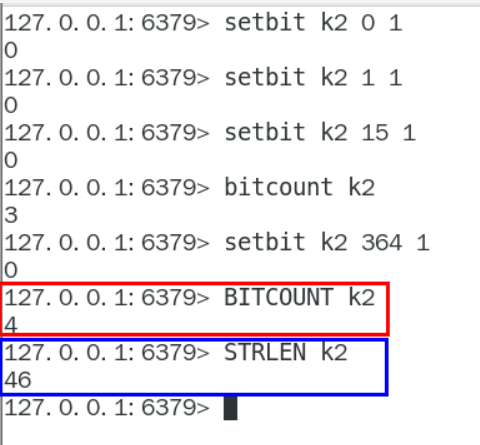
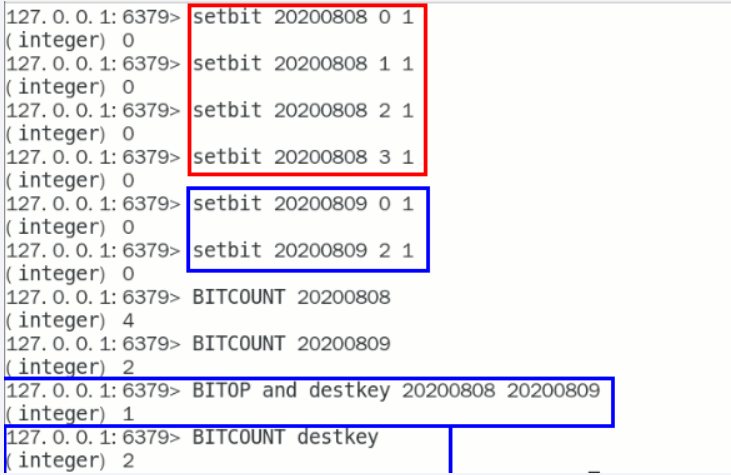
bitop连续2天都签到的用户
加入某个网站或者系统,它的用户有1000W,做个用户id和位置的映射
比如0号位对应用户id:uid-092iok-lkj
比如1号位对应用户id:uid-7388c-xxx

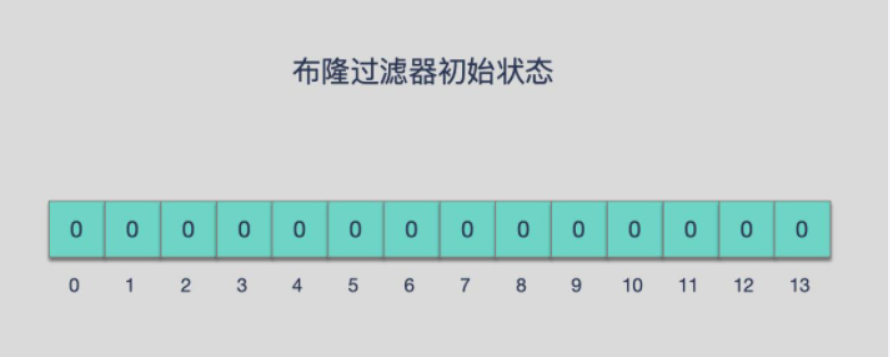
布隆过滤器
由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素
设计思想:
- 本质就是判断具体数据是否存在于一个大的集合中
备注
布隆过滤器是一种类似set的数据结构,只是统计结果在巨量数据下有点瑕疵,不够完美。
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。
它实际上是一个很长的二进制数组(00000000)+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
链表、树、哈希表等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生

布隆过滤器高效地插入和查询,占用空间少,返回的结果是不够确定+不够完美
| 目的 | 减少内存占用 |
|---|---|
| 方式 | 不保存数据信息,只是在内存中做一个是否存在的标记flag |
一个元素如果判断结果:存在时,元素不一定存在,但是判断结果为不存在时,则一定不存在。
布隆过滤器可以添加元素,但是不能删除元素,由于设计hashcode判断依据,删掉元素会导致误判率增加。
- 总结:
- 有,是可能有
- 无,是肯定无
- 可以保证的是,如果布隆过滤器判断一个元素不在一个集合中,那这个元素一定不会在集合中
原理:布隆(Bloom Filter)过滤器——全面讲解,建议收藏-CSDN博客
使用场景
解决缓存穿透的问题,和
redis集合bitmap使用黑名单校验,识别垃圾邮件
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。
假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。
把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。
安全连接网址,全球上10亿的网址判断
案例:
白名单的可以访问,不在白名单的不能访问
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 连接池 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--Mysql数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<!--SpringBoot集成druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!-- mybatis -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.4</version>
</dependency>
<!--通用Mapper-->
<dependency>
<groupId>tk.mybatis</groupId>
<artifactId>mapper</artifactId>
<version>4.1.5</version>
</dependency>yaml
server:
port: 8080
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
username: root
password: root
url: jdbc:mysql://localhost:3306/db01?useUnicode=true&characterEncoding=utf-8&useSSL=false
druid:
test-while-idle: false
driver-class-name: com.mysql.jdbc.Driver
application:
name: Redis7_study
swagger2:
enable: true # 是否开启swagger
data:
redis:
host: 192.168.0.133 # redis IP 地址
database: 0 # redis 0号数据库
port: 6379 # redis 端口
password: redis # redis 密码
mybatis:
type-aliases-package: com.lazy.pojo
configuration:
map-underscore-to-camel-case: true
mapper-locations: classpath:mapper/*.xml实体类
package com.lazy.pojo;
import lombok.Data;
import javax.persistence.Id;
import javax.persistence.Table;
import java.util.Date;
@Data
@Table(name = "t_customer")
public class Customer {
@Id
private Integer id;
private String cname;
private Integer age;
private String phone;
private Boolean sex;
private Date birth;
}service
package com.lazy.service;
import com.lazy.mapper.CustomerMapper;
import com.lazy.pojo.Customer;
import com.lazy.utlis.CheckUtils;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
@Service
@Slf4j
public class CustomerService {
@Resource
private CustomerMapper customerMapper;
@Resource
private RedisTemplate<String, Object> redisTemplate;
public static final String CUSTOMER_KEY = "customer:";
@Resource
private CheckUtils checkUtils;
public void addCustomer(Customer customer) {
int result = customerMapper.insert(customer);
if (result > 0) {
customer = customerMapper.selectByPrimaryKey(customer.getId());
redisTemplate.opsForValue().set(CUSTOMER_KEY + customer.getId(), customer);
}
}
public Customer findCustomerById(Integer id) {
Customer customer;
customer = (Customer) redisTemplate.opsForValue().get(CUSTOMER_KEY + id);
if (customer == null) {
//缓存没有,查询数据库
customer = customerMapper.selectByPrimaryKey(id);
if (customer != null) {
//缓存有,缓存到redis中
redisTemplate.opsForValue().set(CUSTOMER_KEY + id, customer);
}
}
return customer;
}
public Customer findCustomerByIdWithBloomFilter(Integer id) {
String key = CUSTOMER_KEY + id;
Customer customer;
if (!checkUtils.checkWithBloomFilter("whitelistCustomer", key)){
log.info("白名单暂无此信息:{}",key);
return null;
}
customer = (Customer) redisTemplate.opsForValue().get(key);
if (customer == null) {
//缓存没有,查询数据库
customer = customerMapper.selectByPrimaryKey(id);
if (customer != null) {
//缓存有,缓存到redis中
redisTemplate.opsForValue().set(CUSTOMER_KEY + id, customer);
}
}
return customer;
}
}controller
package com.lazy.controller;
import com.lazy.pojo.Customer;
import com.lazy.service.CustomerService;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.util.Date;
import java.util.Random;
import java.util.UUID;
@RestController
public class CustomerController {
@Resource
private CustomerService customerService;
@GetMapping("/customer/add")
public Customer addCustomer() {
Customer customer = new Customer();
customer.setId(1);
customer.setAge(new Random().nextInt(60));
customer.setSex(true);
customer.setPhone("131412421");
customer.setCname("zs");
customer.setBirth(Date.from(LocalDateTime.now().atZone(ZoneId.systemDefault()).toInstant()));
customerService.addCustomer(customer);
return customer;
}
@GetMapping("/customer/get/{id}")
public Customer getCustomerById(@PathVariable Integer id) {
return customerService.findCustomerById(id);
}
@GetMapping("/customerWithBloomFilter/get/{id}")
public Customer getCustomerByIdWithBloomFilter(@PathVariable Integer id) {
return customerService.findCustomerByIdWithBloomFilter(id);
}
}检查是否是在白名单工具类
package com.lazy.utlis;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
/**
* 检查是否有白名单
*/
@Component
@Slf4j
public class CheckUtils {
@Resource
private RedisTemplate<String, Object> redisTemplate;
public Boolean checkWithBloomFilter(String checkItem,String key){
int hashValue = Math.abs(key.hashCode());//获得hashcode值
long index = (long)(hashValue % Math.pow(2,32));//得到对应槽位,2的32次方是int类型
Boolean existOk = redisTemplate.opsForValue().getBit(checkItem, index);
log.info("key:{},对应的坑位是:{},是否存在:{}",key,index,existOk);
return existOk;
}
}